Active Directory Troubleshooting, Auditing, and Best Practices
A Non‐Introduction to Active Directory
The world has been using Active Directory (AD) for more than a decade now, so there's probably little point in doing a traditional introduction for this book. However, there's still a bit of context that we should cover before we get started, and we should definitely think about AD's history as it applies to our topics of troubleshooting, auditing, and best practices.
The real point of this chapter is to identify key elements of AD that you need to completely inventory in your environment before proceeding in this book. Much of the material in the following chapters will refer to specific infrastructure elements, and will make recommendations based on specifics in common AD environments and scenarios. To make the most of those recommendations, you'll need to know the specifics of your own environment so that you know exactly which recommendations apply to you—and a complete, up‐to‐date inventory is the best way to gain that familiarity. To conclude this chapter, I'll briefly outline what's coming up in the chapters ahead.
A Brief AD History and Background
AD was introduced with Windows 2000 Server, and replaced the "NT Domain Services" (NTDS) that had been used since Windows NT 3.1. AD is Microsoft's first real directory; NTDS was pretty much just a flat user account database. AD was designed to be more scalable, more efficient, more standards‐based, and more modern that its predecessor. However, AD was (and is) still built on the Windows operating system (OS), and as such shares some of the OS's particular patterns, technologies, eccentricities, and other characteristics.
AD also integrated a successor to Microsoft's then‐nascent registry‐based management tools. Known today as Group Policy, this new feature added significant roles to the directory beyond the normal one of authentication. With Group Policy, you can centrally define and assign literally thousands of configuration settings to Windows computers (and even non‐Windows computers, with the right add‐ins) belonging to the domain.
When AD was introduced, security auditing was something that relatively few companies worried about. Since 2000, numerous legislative and industry regulations throughout the world have made security and privacy auditing much more commonplace, although AD's native auditing capabilities have changed very little throughout that time. Because of its central role in authentication and configuration management, AD occupies a critical role for security operations, management, and review within organizations.
We also have to recognize that, outside from governing permissions on its own objects, AD doesn't play a central role in authorization. That is, permissions on things like files, folders, mailboxes, databases, and so forth aren't managed within AD. Instead, those permissions are managed at their point, meaning they're managed on your file servers, mail servers, database servers, and so forth. Those servers may assign permissions to identities that are authenticated by AD, but those servers control who actually has access to what. This division of labor between authentication and authorization makes for a highly‐scalable, robust environment, but it also creates significant challenges when it comes to security management and auditing because there's no central place to control or review all of those permissions.
Over the past decade, we've learned a lot about how AD should be built and managed. Gone are the days when consultants routinely started a new forest by creating an empty root domain; also gone are the days when we believed the domain was the ultimate security boundary and that organizations would only ever have a single forest. In addition to covering troubleshooting and auditing, this book will present some of the current industry best practices around managing and architecting AD.
We've also learned that, although difficult to change, your AD design isn't necessarily permanent. Tools and techniques originally created to help migrate to AD are now used to restructure AD, in effect "migrating" to a new version of a domain as our businesses change, merge, and evolve. This book doesn't specifically focus on mergers and restructures, but keep in mind that those techniques (and tools to support them) are available if you decide that a directory restructure is the best way to proceed for your organization.
Inventorying Your AD
Before we get started, it's important that you have an up‐to‐date, accurate picture of what your directory looks like. This doesn't mean turning to the giant directory diagram that you probably have taped to the wall in your data center or server room, unless you've doublechecked to make sure that thing is up‐to‐date and accurate! Throughout this book, I'll be referring to specific elements of your AD infrastructure, and in some cases, you might even want to consider implementing changes to that infrastructure. In order to best follow along, and make decisions, you'll want to have all of the following elements inventoried.
Forests and Trusts
Most organizations have realized that, given the power of the forest‐level Enterprise Admins group, the AD forest is in fact the top‐level security boundary. Many companies have multiple forests, simply because they have resources that can't all be under the direct control of a single group of administrators. However, to ensure the ability for users, with the appropriate permissions of course, to access resources across forests, cross‐forest trusts are usually defined. Your first inventory should be to define the forests in your organization, determine who controls each forest, and document the trusts that exist between those forests.
Cross‐forest trusts can be one‐way, meaning that if Forest A trusts Forest B, the converse is not necessarily true unless a separate trust has been established so that Forest B explicitly trusts Forest A. Two‐way trusts are also possible, meaning that Forest A and Forest B can trust each other through a single trust connection. Forest trusts are also non‐transitive: If Forest A trusts Forest B, and Forest B trusts Forest C, then Forest A does not trust Forest C unless a separate, explicit trust is created directly between A and C.
When we talk about trust, we're saying that the trusting forest will accept user accounts from the trusted forest. That is, if Forest A trusts Forest B, then user accounts from Forest B can be assigned permissions on resources within Forest A. Forest trusts automatically include every domain within the forest so that if Forest A contains five domains, then every one of those domains would be able to assign permissions to user accounts from Forest B. Each forest consists of a root domain and may also include one or more child domains.
Figure 1.1 shows how you might document your forests. Key elements include meta directory synchronization links, forest trusts, and a general indication of what each forest is used for (such as for users or for resources).
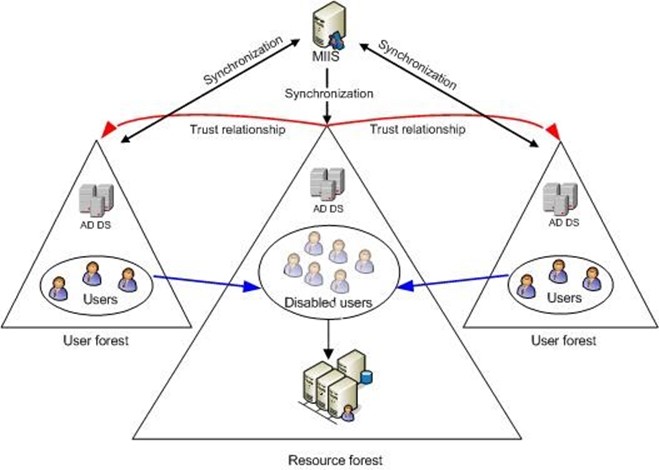
Figure 1.1: Documenting forests.
For the various diagrams in this chapter, I'm going to draw from a variety of sources, including my past consulting engagements and Microsoft documentation. My purpose in doing so is to illustrate that these diagrams can take many different forms, at many different levels of complexity, and with many different levels of sophistication. Consider each of them, and produce your own diagrams using the best tools and skills you have.
Domains and Trusts
Domains act as a kind of security boundary. Although subject to the management of members of the Enterprise Admins group, and to a degree the Domain Admins of the forest root domain, domains are otherwise independently managed by their own Domain Admins group (or whatever group those permissions have been assigned or delegated to).
Account domains are those that have been configured to contain user accounts but which contain no resource servers such as file servers. Resource domains contain only resources such as file servers, and do not contain user accounts. Neither of these designations is strict, and neither exists within AD itself. For example, any resource domain will have at least a few administrator user accounts, user groups, and so forth. The type of domain designation is strictly a human convenience, used to organize domains in our minds. Many companies also use mixed domains, in which both user accounts and resources exist. Domains are typically organized into a tree, beginning with the root domain and then through domains that are configured as children of the root. Domain names reflect this hierarchy: Company.com might be the name of a root domain, and West.Company.com, East.Company.com, and North.Company.com might be child domains. Within such a tree, all domains automatically establish a transitive parent‐child two‐way trust, effectively meaning that each domain trusts each other domain within the same tree.
Forests, as the name implies, can contain multiple domain trees. By default, the root of each tree has a two‐way, transitive trust with the forest root domain (which is the root of the first tree created within that forest), effectively meaning that all domains within a forest trust each other. That's the main reason companies have multiple forests, because the full trust model within a forest gives top‐level forest‐wide control to the forest's Enterprise Admins group.
Even if you rely entirely on these default inter‐domain trusts, it's still important to document them, along with the domains' names. Figure 1.2 shows how you might build a domain diagram in a program like Microsoft Office Visio. The emphasis in this diagram is on the logical domain structure.
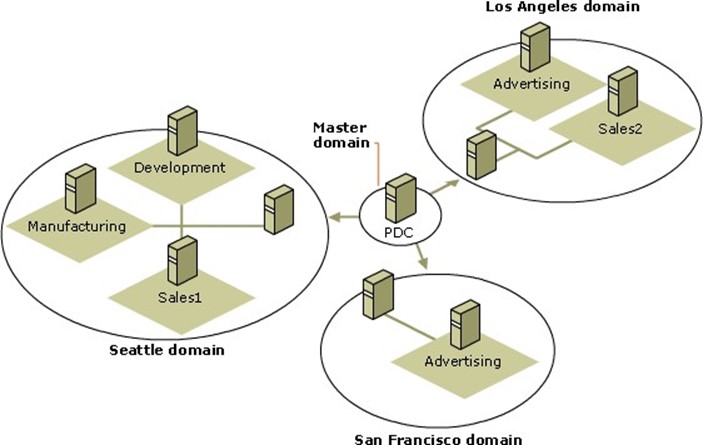
Figure 1.2: Documenting domains.
If you have any specialized domains—such as resource‐only domains, user‐only domains, and so forth—note those in your documentation. Also note the number of objects (especially computer and user accounts) in each domain. That is actually one of the most important metrics you can know about your domains, although many administrators can't immediately recall their numbers.
Domain Controllers
Domain controllers (DCs) are what make AD work. They're the servers that run AD's services, making the directory a reality. It's absolutely crucial, as you start reading this book, that you know how many DCs you have, where they're located, what domains they're in, and their individual IP addresses.
In many environments, DCs also provide other services, most frequently Domain Name Service (DNS). Other roles held by DCs may include WINS and DHCP services.
A DC's main role is to provide authentication services for domain users and for resources within the domain. We typically think of this authentication stuff as happening mainly when users show up for work in the morning—and in most cases, that is when the bulk of the authentication traffic occurs. However, as users attempt to access resources throughout the day, their computer will automatically contact a DC to obtain a Kerberos ticket for those resources. In other words, authentication traffic continues throughout the day—albeit at a somewhat slower, more evenly‐distributed pace than the morning rush.
That morning rush can be significant: Each user's computer must contact a DC to log itself onto the domain, and then again when the user is ready to log on. Users almost always start the day with a few mapped drives, each of which may require a Kerberos ticket, and they usually fire up Outlook, requiring yet another ticket. Some of the organizations I've consulted with have each user interacting with a DC more than a dozen times each morning, and then several dozen more times throughout the day.
We tend to size our DCs for that morning rush, and that capacity generally sees us throughout the day—even if we take the odd DC offline mid‐day for patching or other maintenance.
Each DC maintains a complete, read/write copy of the entire directory (the only exception being new‐fangled readonly domain controllers—RODCs, which as the name implies, contain only a readable copy of the directory). Multi‐master replication ensures that any change made on any DC will eventually propagate to every other DC in the domain. Replication is often one of the trickiest bits of AD, and is one of the things we tend to spend the most time monitoring and troubleshooting. Not all domain data is created equally: Some highpriority data, such as account lockouts, replicate almost immediately (or at least as quickly as possible), while less‐critical information can take much longer to make its way throughout the organization.
Figure 1.3 shows what a DC inventory might look like. Note the emphasis on physical details: IP addresses, DNS configuration, domain membership, and so forth.

Figure 1.3: DC inventory.
It's also important to note whether any of your DCs are performing any non‐AD‐related tasks, such as hosting a SQL Server instance (which isn't recommended), running IIS, and so forth.
Global Catalogs
A global catalog (GC) is a specific service that can be offered by a DC in addition to its usual DC duties. The GC contains a subset of information about every object in an entire forest, and enables users in each domain to discover information from other domains in the same forest. Each domain needs at least one GC; however, given the popularity of Exchange Server and its heavy dependence on GCs (Outlook, for example, relies on GCs to do email address resolution), it's not unusual to see a majority, or even all, DCs in a domain configured as GC servers.
Make sure you know exactly where your GCs are located. Numerous network operations can be hindered by a paucity of GCs, but having too many GCs can significantly increase the replication burden on your network.
In Figure 1.3, "GC" is used to indicate DCs that are also hosting the GC server role.
FSMOs
Certain operations within a domain, and within a forest, need a single DC to be in charge. It is absolutely essential for most troubleshooting processes that you know where these Flexible Single Master of Operation (FSMO) role‐holders sit within your infrastructure:
- The RID Master is in charge of handing out Relative IDs (RIDs) within a single domain (and so you'll have one RID Master per domain). RIDs are used to uniquely identify new AD objects, and they are assigned in batches to DCs. If a DC runs out of RIDs and can't get more, that DC can't create new objects. It's common to put the RID Master role on a DC that's used by administrators to create new accounts so that that DC will always be able to request RIDs.
- The Infrastructure Master maintains security identifiers for objects referenced in other domains—typically, that means updating user and group links. You have one of these per domain.
- The PDC Emulator provides backward‐compatibility with the old NTDS, and is the only place where NTDS‐style changes can be made (any DC provides read access for NTDS clients). Given that NTDS clients are becoming extinct in most organizations, the PDC Emulator (you'll have one in each of your domains, by the way) doesn't get used a lot for that purpose. Fortunately, it has a few other things to keep it busy. For example, password changes processed by other DCs tend to replicate to the PDC Emulator first, and the PDC Emulator serves as the authoritative time source for time synchronization within a domain.
- Each forest will contain a single Schema Master, which is responsible for handling schema modifications for the forest.
- Each forest also has a Domain Naming Master, which keeps track of the domains in the forest, and which is required when adding or removing domains to or from the forest. The Domain Naming Master also plays a role in maintaining group membership across the forest.
Marking these role owners on your main diagram (such as Figure 1.3) is a great way to document the FSMO locations. Some organizations also like to indicate a "backup" DC for each FSMO role so that in the event a FSMO role must be moved, it's clear where it should be moved to.
Containers
The logical structure of AD is divided into a set of hierarchical containers. AD supports two main types: containers and organizational units (OUs). A couple of built‐in containers (such as the Users container) exist by default within a domain, and you can create all the OUs that you want to help organize your domain's objects and resources. Again, an inventory here is critical, as several operations—most especially Group Policy application—work primarily based on things like OU membership.
Figure 1.4 shows one way in which you might document your OU and container hierarchy. Depending on the size and depth of your hierarchy, you could also just grab a screenshot from a program like Active Directory Users and Computers.
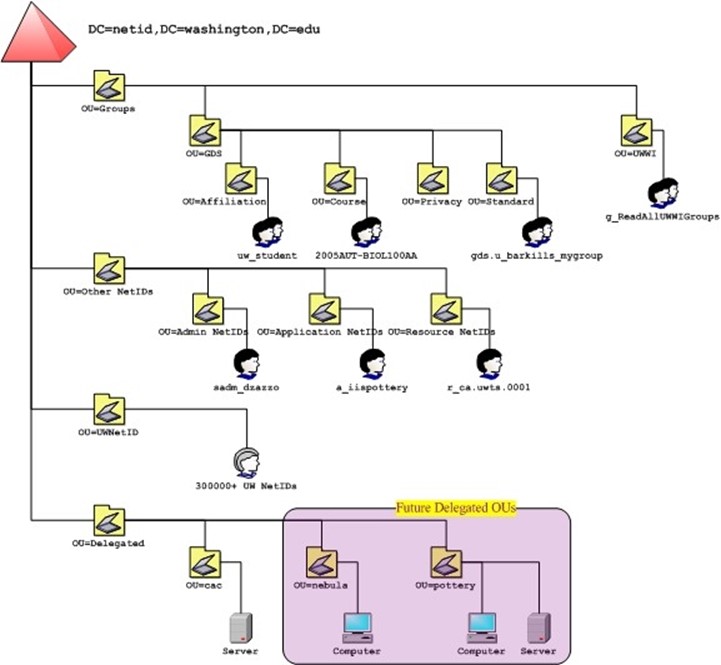
Figure 1.4: Documenting OUs and containers.
Try to make some notation of how many objects are in each container, and if possible make a note of which containers have which Group Policy Objects (GPOs) linked to them. That information will be useful as we dive into troubleshooting and best practices discussions.
Subnets, Sites, and Links
In AD terms, a subnet is an entry in the directory that defines a single network subnet, such as 192.168.1.0/8. A site is a collection of subnets that all share local area network (LAN)style connectivity, typically 100Mbps or faster. In other words, a site consists of all the subnets in a given geographic location.
Links, or site links, define the physical or logical connectivity between sites. These tell AD's replication algorithms which DCs are able to physically communicate across wide area network (WAN) links so that replicated data can make its way throughout the organization. Documenting your subnets, sites, and links is quite probably the most important inventory you can have for a geographically‐dispersed domain.
Typically, you'll have site links that represent the physical WAN connectivity between sites. A cost can be applied to each link, indicating its relative expense. For example, if two sites are connected by a high‐speed WAN link and a lower‐speed backup link, the backup link might be given a higher cost to discourage its use by AD under normal conditions. As Figure 1.5 shows, you can also create site links that represent a virtual connection. The A‐C link connects two sites that do not have direct WAN connectivity. This isn't necessarily a best practice, as it tells AD to expect WAN connectivity where none in fact exists.
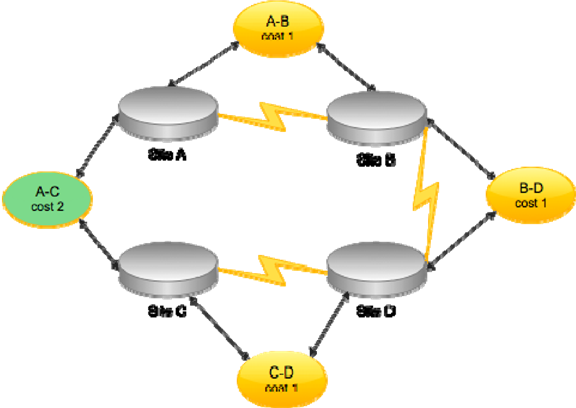
Figure 1.5: Configuring site links.
Eliminating the A‐C site link will not hinder AD operations: The directory will correctly determine the best path for replication. For example, changes made in Site C would replicate to D, then to B, and eventually to A. If Site C were the source of many changes (perhaps a concentration of administrators work there), you could speed up replication from there to Site A by creating a site link bridge, effectively informing AD of the complete path from C to A by leveraging the existing A‐B, B‐D, and C‐D site links. Such a bridge accurately reflects the physical WAN topology but provides a higher‐priority route from C to A. Figure 1.6 shows how you might document that.
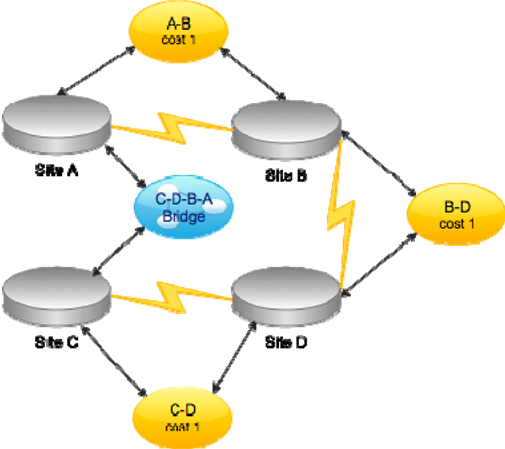
Figure 1.6: Configuring a site link bridge.
As you document your sites, think again about numbers: How many computers are in each site? How many users? Make a notation of these numbers, along with a notation of how many DCs exist at each site.
Sites should, as much as possible, reflect the physical reality of your network; they don't correspond to the logical structure of the domain in any way. One site may contain DCs from several domains or forests, and any given domain may easily span multiple sites. However, site links are kind of a part of the domain's logical structure because those links are defined within the directory itself. If you have multiple domains, it's worth building a diagram (like Figure 1.5 or 1.6) for each domain—even if they look substantially the same. In fact, any group of domains that spans the same physical sites should have identicallooking site diagrams because the physical reality of your network isn't changing. Going through the exercise of creating the diagrams will help ensure that each domain has its links and bridges configured properly.
DNS
The last critical piece of your inventory consists of your DNS servers. You should clearly document where each server physically sits and think about which clients it serves. Most companies have at least two DNS servers, although having more (and distributing them throughout your network) can provide better DNS performance to distant clients. AD absolutely cannot function without DNS, so it's important that both servers and clients have ready access to a high‐performance DNS server. Most AD problems are rooted in DNS issues, meaning much of our troubleshooting discussion will be about DNS, and that discussion will be more meaningful if you can quickly locate your DNS servers on your network.
Also try to make some notation of which users, and how many users, utilize each DNS server either as a primary, secondary, or other server. That will help give you an at‐aglance view of each DNS server's workload, and give you an idea of which users are relying on a particular server.
Putting Your Inventory into Visual Form
A tool like Microsoft Office Visio is often utilized to create AD infrastructure diagrams, often showing both the logical structure (domains, forests, and trusts) and the physical topology (subnets, sites, links, and so forth). There are also third‐party tools that can automatically discover your infrastructure elements and create the appropriate charts and diagrams for you. The benefit of such tools is that they're always right because they're reflecting reality— not someone's memory of reality. They can usually catch changes and create updated diagrams much faster and more accurately than you can.
I love to use those kinds of tools in combination with my own hand‐drawn diagrams. If the tool‐generated picture of my topology doesn't match my own picture, I know I've got a problem, and that can trigger an investigation and a change, if needed.
What's Ahead
Let's wrap up this brief introduction with a look at what's coming up in the next seven chapters.
AD Troubleshooting
Chapters 2 and 3 will concern themselves primarily with troubleshooting. In Chapter 2, we'll focus on the ways and means of monitoring AD, including native event logs, system tools, command‐line tools, network monitors, and more. I'll also present desirable capabilities available in third‐party tools (both free and commercial), with a goal of helping you to build a sort of "shopping list" of features that may support troubleshooting, security, auditing, and other needs.
Chapter 3 will focus on troubleshooting, including techniques for narrowing the problem domain, addressing network issues, resolving name resolution problems, dealing with AD service issues, and more. We'll also look at replication, AD database failures, Group Policy issues, and even some of the things that can go wrong with Kerberos. I'll present this information in the form of a troubleshooting flowchart that was developed by a leading AD Most Valuable Professional (MVP) award recipient, and walk you through the tools and tasks necessary to troubleshoot each kind of problem.
I'll wrap up this book with more troubleshooting, devoting Chapter 8 to additional troubleshooting tips and tricks.
AD Security
In Chapter 4, we'll dive into and discuss the base architecture for AD security. We'll look more at the issue of distributed permissions management, and discuss some of the problems that it presents—and some of the advantages it offers. We'll look at some do‐ityourself tools for centralizing permissions changes and reporting, and explore whether you should rethink your AD security design. We'll also look at third‐party capabilities that can make security management easier, and dive into the little‐understood topic of DNS security.
AD Auditing
Chapter 5 will cover auditing, discussing AD's native auditing architecture and looking at how well that architecture helps to meet modern auditing requirements. I'll also present capabilities that are offered by third‐party tools and how well those can meet today's business requirements and goals.
AD Best Practices
Chapter 6 will be a roundup of best practices for AD, including a quick look at whether you should reconsider your current AD domain and forest design (and, if you do, how you can migrate to that new design with minimum risk and effort). We'll also look at best practices for disaster recovery, restoration, security, replication, FSMO placement, DNS design, and more. I'll present new ideas for virtualizing your AD infrastructure, and look at best practices for ongoing maintenance.
Monitoring Active Directory
The fact is that you can't really do anything with Active Directory (AD) unless you have some way of figuring out what's going on under the hood. That's what this chapter will be all about: how to monitor AD. I have to make a distinction between monitoring and auditing: Monitoring, which we'll cover here, is primarily done to keep an eye on functionality and performance, and to solve functional and performance problems when they arise. Auditing is an activity designed to keep an eye on what people are doing with the directory—exercising permissions, changing the configuration, and so forth. We have chapters on auditing lined up for later in this book.
Monitoring Goals
There are really two reasons to monitor AD. The first is because there's some kind of problem that you're trying to solve. In those cases, you're usually interested in current information, delivered in real‐time, and you're not necessarily interested in storing that data for more than a few moments. That is, you want to see what's happening right now. You also usually want to focus in on specific data, such as that related to replication, user logon performance, or whatever you're troubleshooting.
The second reason to monitor is for trending purposes. That is, you're not looking at a specific problem but instead collecting data so that you can spot potential problems. You're usually looking at a much broader array of data because you don't have anything specific that you need to focus on. You're also usually interested in retaining that data for a potentially long time so that you can detect trends. For example, if user logon workload is slowly growing over time, storing monitoring data and examining trends—perhaps in the form of charts—allows you to spot that growing trend, anticipate what you might need to do about it, and get it done.
Having these goals in mind as we look at some of the available tools is important. Some tools excel at offering real‐time data but are poor at storing data that would provide trending information. Other tools might be great at storing information for long‐term trending but aren't as good at providing highly‐detailed, very‐specific, real‐time information for troubleshooting purposes. So as we look at these tools, we'll try to identify which bits they're good at.
Another thing to keep in mind before we jump in is that some of these tools are actually foundational technologies. In other words, when we discuss event logs, you have to keep in mind that that technology is a tool that you can use—and it's a foundation that other tools use. Any strengths or weaknesses present in that technology are going to carry through to any tools that use that technology. So again, it's simply important to recognize such considerations because they'll have an impact beyond that specific tool.
Event Logs
Windows' native event logs play a crucial role in monitoring AD. The event logs aren't great, but they're the place where AD sends a decent amount of diagnostic and auditing information, so you have to get used to using them.
There's a bit of a distinction that needs to be made: The event log is a native Windows data store. The Event Viewer is the native tool that enables you to look at these logs. Event logs themselves are also accessible to a wide variety of other tools, including Windows PowerShell, Windows Management Instrumentation (WMI), and numerous third‐party tools. In Windows Server 2008 and later, these logs' Viewer is accessible through the
Server Manager console, which Figure 2.1 shows.
Figure 2.1: Accessing event logs in Server Manager.
There are two kinds of logs. The Windows Logs are the same basic logs that have been around since the first version of Windows NT. Of these, Active Directory (AD) writes primarily to the Security log (auditing information) and the System log (diagnostic information). In Windows Server 2008, a new kind of log, Applications and Services Logs, were introduced. These supplement the Windows Logs by giving each application the ability to create and write to its own log rather than dumping everything into the Application log, as was done in the past. In these new logs, AD creates an Active Directory Web Services log, DFS Replication log, Directory Service log, and DNS Server log. Technically, DFS and DNS aren't part of AD, but they do integrate with and support AD, so they're important to look at.
Windows itself also creates numerous logs under the Microsoft folder, as Figure 2.1 shows: GroupPolicy, DNS Client Events, and a few others, all of which can offer clues into AD's operation and performance. Don't forget that client computers play a role in AD, as well. Logs for NTLM, Winlogon, DNS Client, and so forth can all provide useful information when you're troubleshooting an AD problem.
Although the event logs can contain a wealth of information, their usefulness can be hit or miss. For example, the event that Figure 2.2 shows is pretty clear: Smart card logons aren't working because there isn't a certificate installed. My domain doesn't use smart card logons, so this is expected and doesn't present a problem.
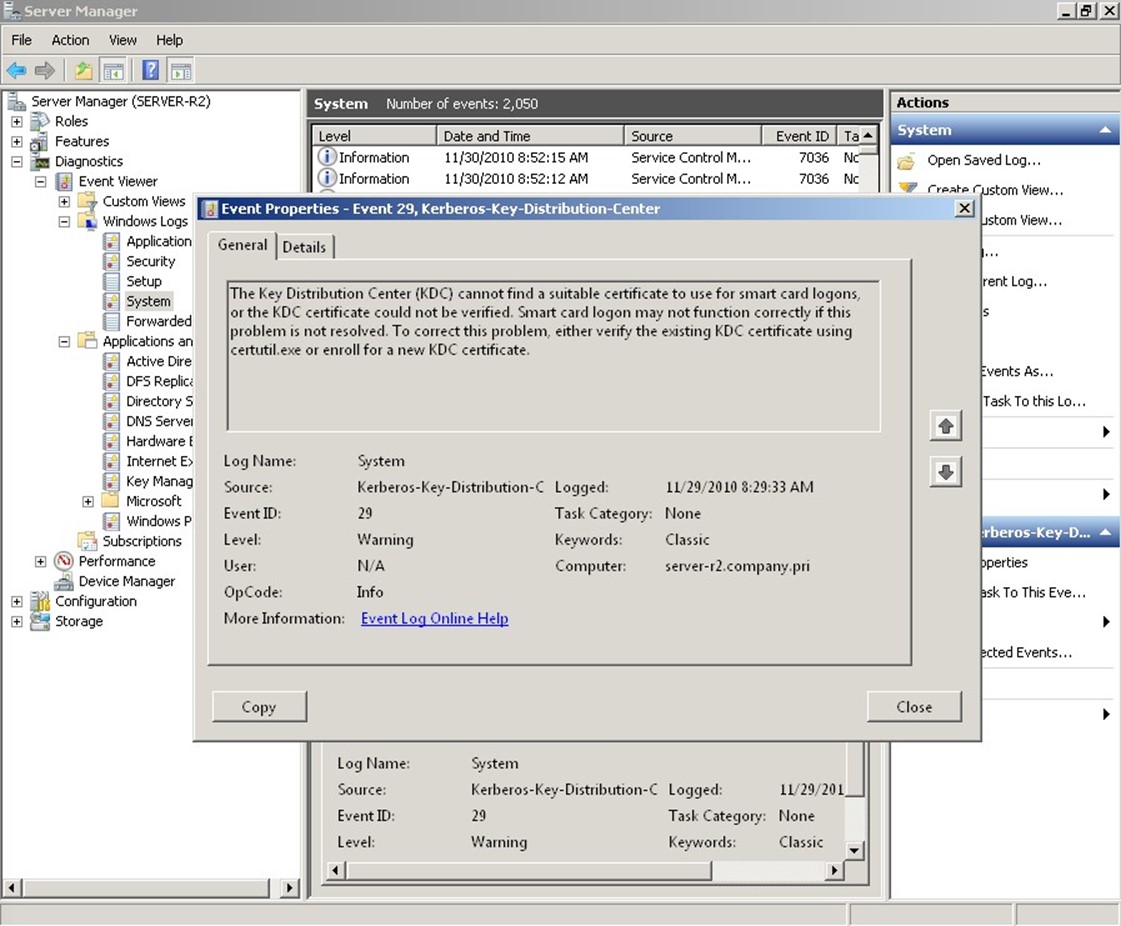
Figure 2.2: Helpful events.
Other events just constitute "noise," such as the one shown in Figure 2.3: User Logon Notification for Customer Experience Improvement Program. Huh? Why do I care?
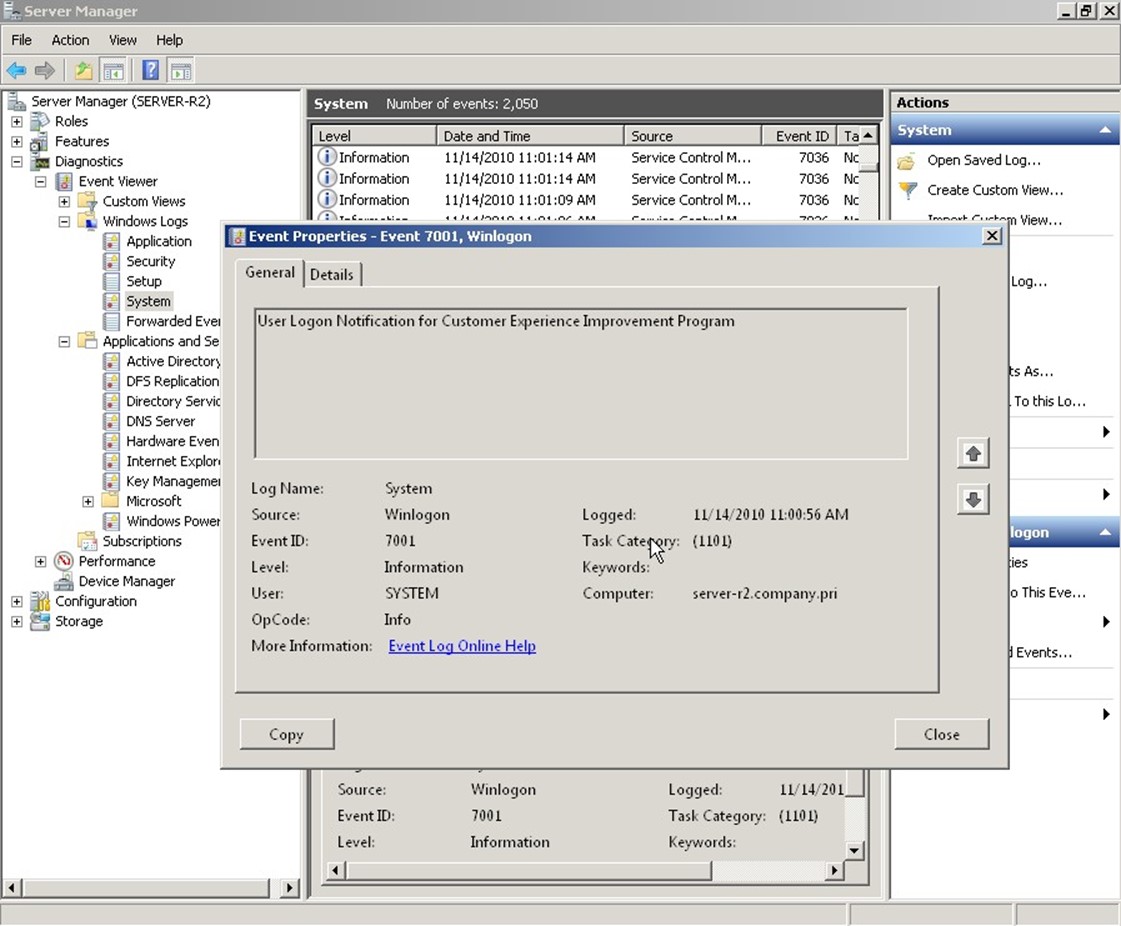
Figure 2.3: "Noise" events.
Then you've got winners like the one shown in Figure 2.4. This is tagged as an actual error, but it doesn't tell me much—and it doesn't give many clues about how to solve the problem or even if I need to worry about it.
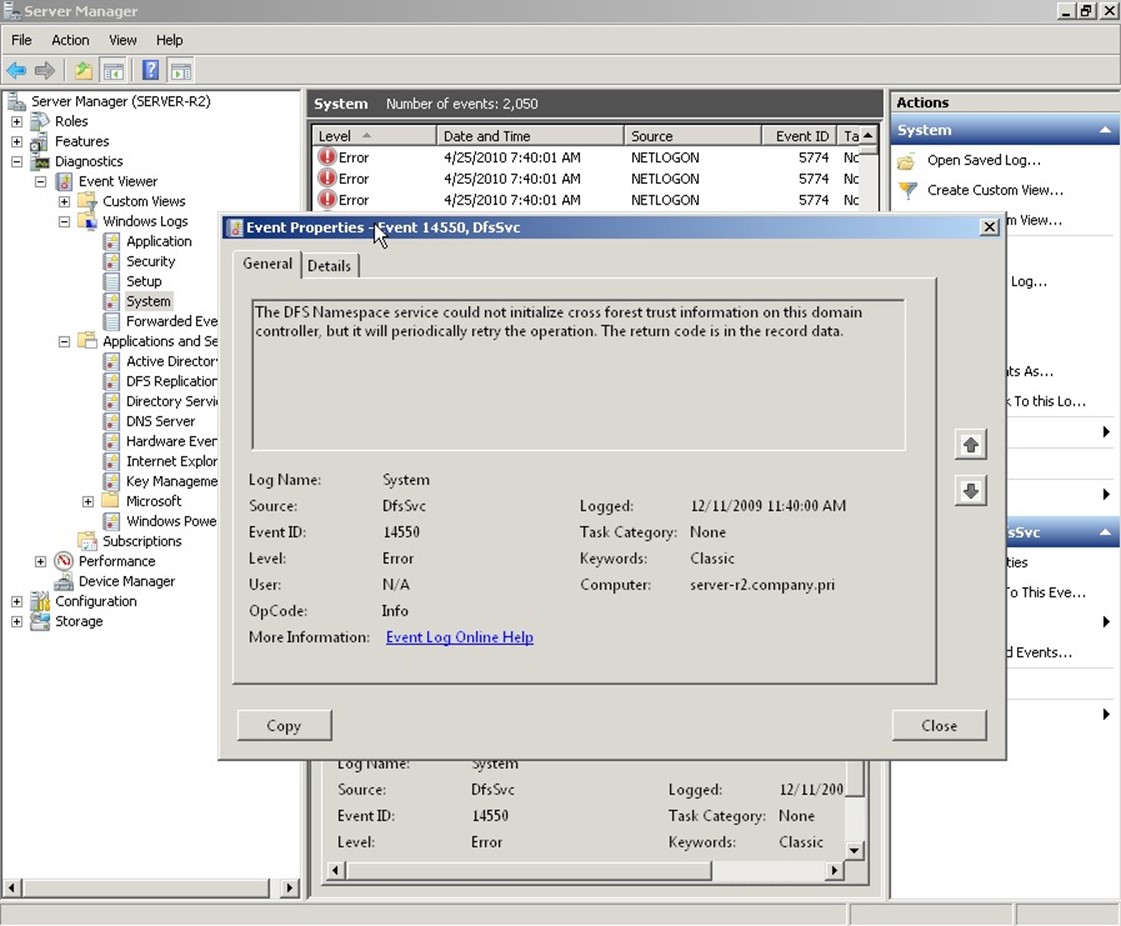
Figure 2.4: Unhelpful events.
It's probably going too far to call this event "useless," but this event is certainly not very helpful. Finally, as shown in Figure 2.5, sometimes the event logs will include suggestions. That's nice, but is this the best place to put these? They create more "noise" when you're trying to track down information related to a specific problem, and they're tagged as Warnings (so you tend to want to look at them, just in case they're warning you of a problem), but they can often be ignored.
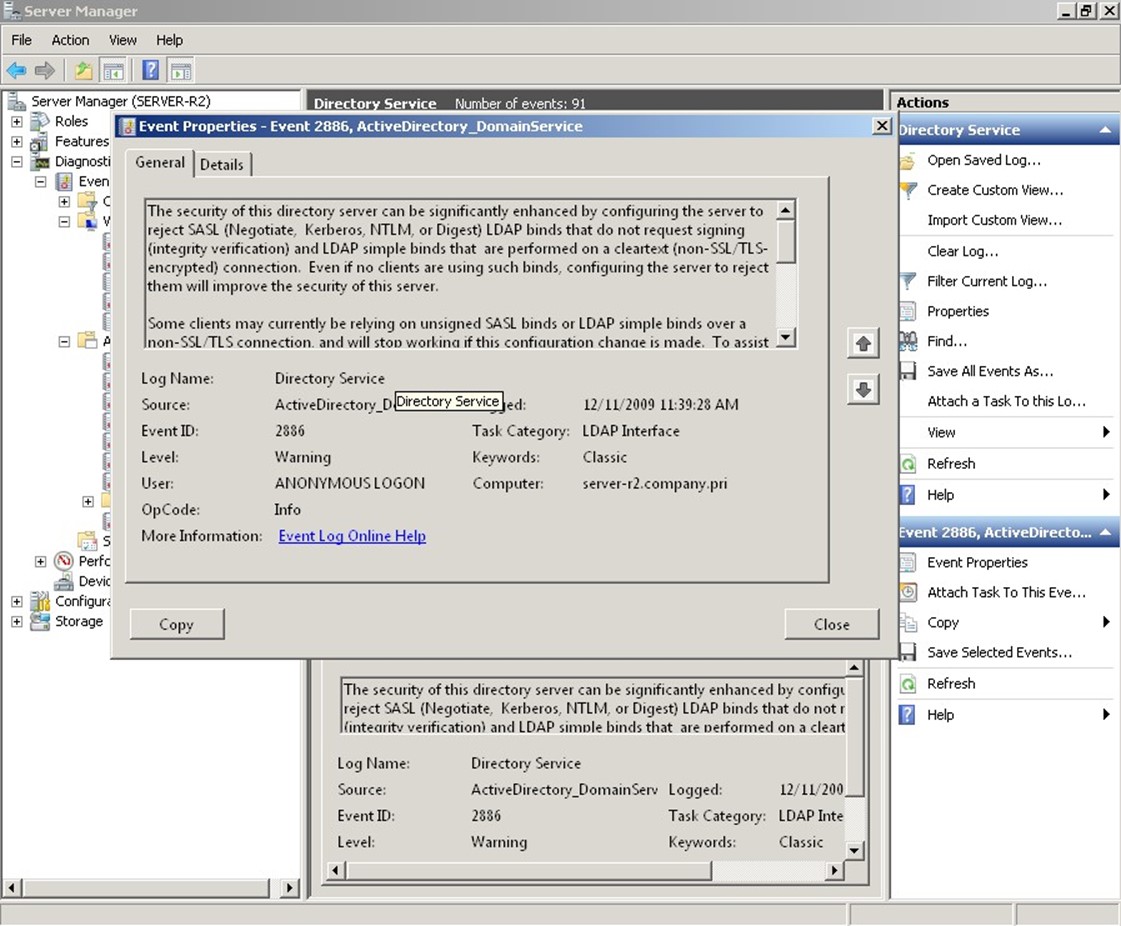
Figure 2.5: Suggestions, not "events."
There probably isn't an administrator alive who hasn't spent a significant amount of time in Google hunting down the meaning behind—and resolution for—dozens of event IDs over the course of their careers. That reality highlights key problems of the native event logs:
- They're not centralized. Although you can configure event forwarding, it's pretty painful to get all of your domain controllers' logs into a single location. That means your diagnostic information is spread across multiple servers, giving you multiple places to search when you're trying to solve a problem.
- They're not always very clear. Confusing, vague, or obtuse messages are what the event logs are famous for. Although Microsoft has gradually improved that over the years in some instances, there are still plenty of poor examples in the logs.
- They're full of noise. Worse, you can't rely on the "Information," "Warning," and "Error" tags. Sometimes, an "Information" event will give you the clue you need to solve a problem, and "Warning" events—as we've seen—can contain information that is not trouble‐related.
- The native Viewer tool offers poor filtering and searching capabilities, and no correlation capability. That is, it can't help you spot related events that might point to a specific problem or solution.
Problems notwithstanding, you have to get used to these logs because they're the only place where AD and its various companions log any kind of diagnostic information when problems occur.
System Monitor/Performance Monitor
Also located in Server Manager is Performance Monitor, the native GUI‐based tool used to view Windows' built‐in performance counters. Any domain controller will contain numerous counter sets related to directory services, including several DFS‐related categories, DirectoryServices, DNS, and more. These are designed to provide the focused, real‐time information you need when you're troubleshooting specific problems—typically, performance problems, although not necessarily. Although Performance Monitor does have the ability to create logs, containing performance data collected over a long period of time, it's not a great tool for doing so. More on that in a bit.
It's difficult to give you a fixed list of counters that you should always look at; any of them might be useful when you're troubleshooting a specific problem. That said, there are a few that are useful for monitoring AD performance in general:
- DRA Inbound Bytes Total/Sec shows inbound replication traffic. If it's zero, there's no replication, which is generally a problem unless you have only one domain controller.
- DRA Inbound Object Updates Remaining in Packet provides the number of directory objects that have been received but not yet applied. This number should always be low on average, although it may spike as replicated objects arrive. If it remains high, your server isn't processing updates quickly.
- DRA Outbound Bytes Total/Sec offers the data being sent from the server due to replication. Again, unless you've got only one domain controller, this will rarely be zero in a normal environment.
- DRA Pending Replication Synchronization shows the number of directory objects waiting to be synchronized. This may spike but should be low on average.
- DS Threads in Use provides the number of process threads currently servicing clients. Continuously high numbers suggest a need for a larger number of processor cores to run those threads in parallel.
- Kerberos Authentications offers a basic measure of authentication workload.
- LDAP Bind Time shows the number of milliseconds that the last LDAP bind took to complete. This should be low on average; if it remains high, the server isn't keeping up with demand.
- LDAP Client Sessions is another basic unit of workload measurement.
- LDAP Searches/Sec offers another good basic unit of workload measurement.
All of these counters benefit from trending, as they all help you form a basic picture of how busy a domain controller is. In other words, it's great when you can capture this kind of data on a continuous basis, then view charts to see how it changes over time. Performance Monitor itself isn't a great tool for doing that because it simply wasn't designed to collect weeks and weeks worth of data and display it in any meaningful way. However, it can be suitable for collecting data for shorter periods of time—say, a few hours—then using the collected data to get a sense of your general workload.
You'll have to do that monitoring on each domain controller, too, because the performance information is local to each computer. Ideally, each domain controller's workload will be roughly equal. If they're not, start looking at things like other tasks the computer is performing, or the computer's hardware, to see why one domain controller seems to be working harder than others.
This kind of performance monitoring is one of the biggest markets for third‐party tools, which we'll discuss toward the end of this chapter. Using the same underlying performance counters, third‐party tools (as well as additional, commercial tools from Microsoft) can provide better performance data collection, storage, trending, and reporting—and can even do a better job of sending alerts when performance data exceeds pre‐set thresholds. What Performance Monitor is good at—as Figure 2.6 shows—is enabling you to quickly view real‐time data when you're focusing on a specific problem.
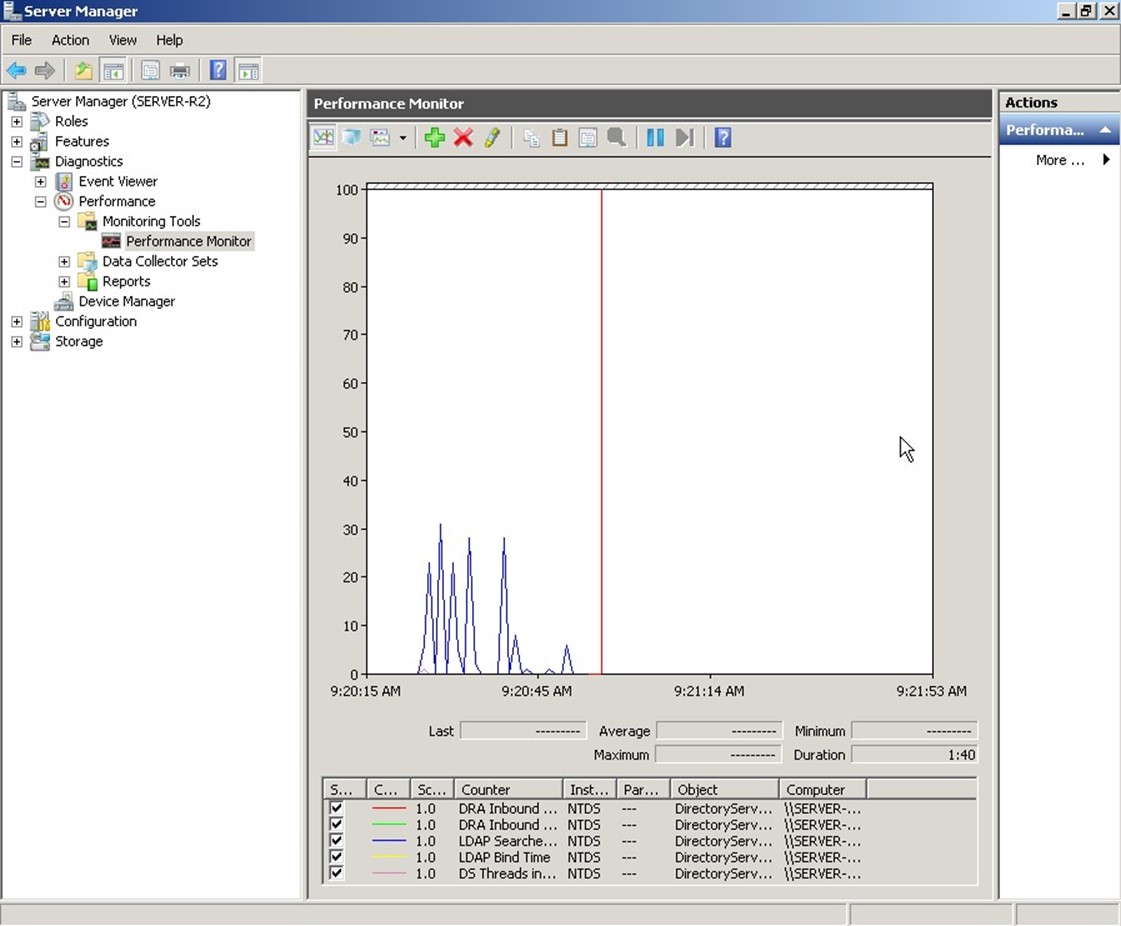
Figure 2.6: Viewing realtime performance data in Performance Monitor.
One problem we should identify, though, is that Performance Monitor requires a good deal of knowledge on your part to be useful. First, you have to make sure you're looking at all the right counters at the right time. Looking at DS Threads alone is useless unless you're also looking at some other counters to tell you why all those threads are, or are not, in use. In other words, you have to be able to mentally correlate the information from many counters to get an accurate assessment of how AD is really performing. Microsoft helps by providing predefined data collector sets, which can include not only counters but also trace logs and configuration changes. One is provided for AD diagnostics (see Figure 2.7).
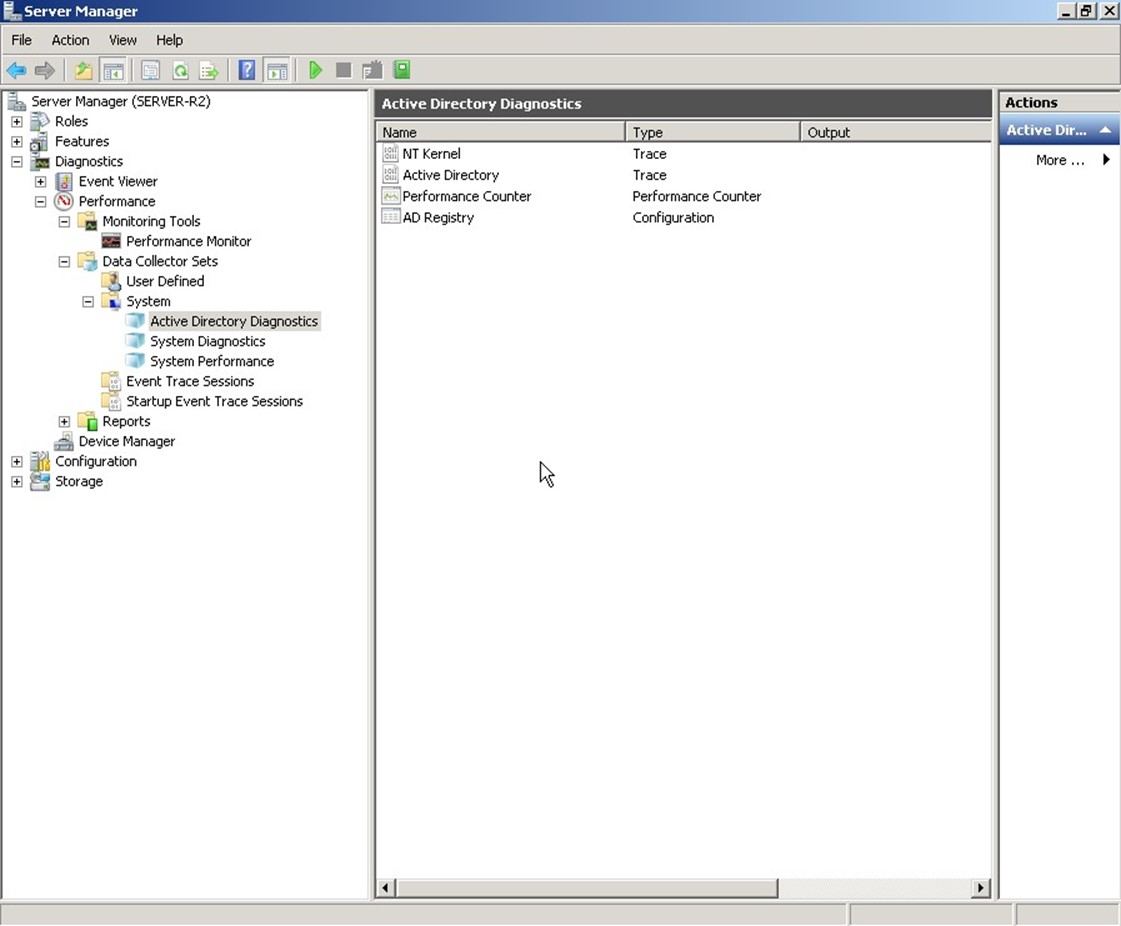
Figure 2.7: The AD Diagnostics data collector set.
Once you start a collector set, you can let it run for however long you like. Results aren't displayed in real‐time; instead, you have to view the latest report, which is a snapshot. These sets are designed to run for longer periods of time than a normal counter trace log, and the sets' configuration includes settings for managing the collected log size. Figure 2.8 shows an example report.

Figure 2.8: Viewing a data collector set report.
These reports do a decent job of applying some intelligence to the underlying data. As you can see here, a "green light" icon lets you know that particular components are performing within Microsoft's recommended thresholds. That "intelligence" doesn't extend far, though: Once you start digging into AD‐specific stuff, you're still looking at raw data, as you can see in the section on Replication that's been expanded in Figure 2.8. Thus, you'll still need a decent amount of expertise to interpret these reports and determine whether they represent a problem condition.
Command‐Line Tools
A host of command‐line tools can help detect AD problems or provide information needed to solve those problems. This chapter isn't intended to provide a comprehensive list of them, but one of the more well‐known and useful ones includes Repadmin. This tool can be used to check replication status and diagnose replication problems. For example, as Figure 2.9 shows, this tool can be used to check a domain controller's replication neighbors—a way of checking on your environment's replication topology. You'll also see if any replication attempts with those neighbors have succeeded or failed.
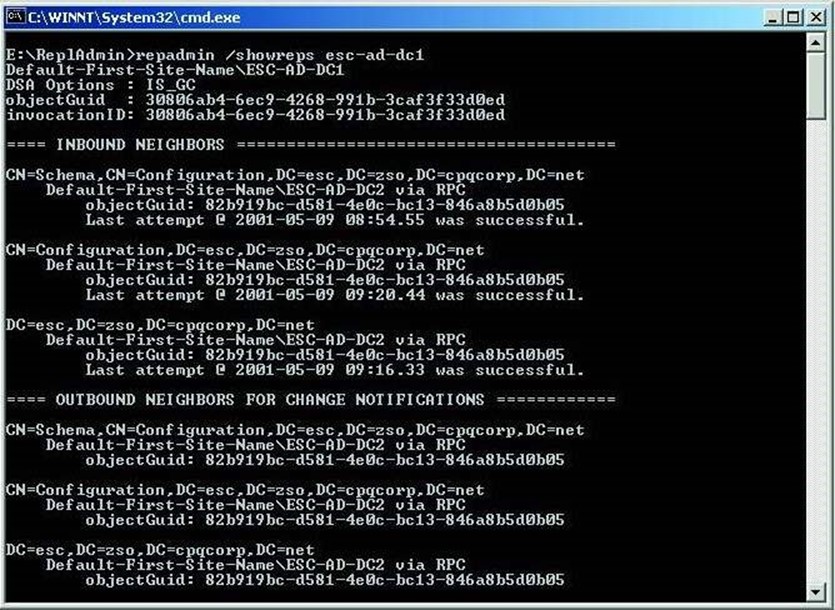
Figure 2.9: Using Repadmin to check replication status.
This—and other command‐line tools—are great for checking real‐time status information. What they're not good at is collecting information over the long haul, or for running continuously and proactively alerting you to problems.
Network Monitor
You might not ordinarily think of Network Monitor—or any packet‐capture tool, including Wireshark and others—as a way of monitoring AD. In fact, with a lot of practice, they can be great tools. After all, much of what AD does ultimately comes down to network communications, and with a packet capture tool, you can easily see exactly what's transpiring over the network. Figure 2.10 illustrates the main difficulty in using these tools.
Figure 2.10: Captured AD traffic in Network Monitor.
You see the problem, right? This is rocket science‐level stuff. I'm showing a captured packet for directory services traffic, but unless you know what this traffic should look like, it's impossible to tell whether this represents a problem. But gaining that knowledge is worth the time: I've used tools like this to find problems with DNS, Kerberos, time sync, and numerous other AD‐related issues. Unfortunately, a complete discussion of these protocols, how they work, and what they should look like is far beyond the scope of this book.
At a simpler level, though, you can use packet capture tools as a kind of low‐level workload monitor. For example, consider Figure 2.11.

Figure 2.11: Capturing traffic in Network Monitor.
Ignoring the details of the protocol, pay attention to the middle frame. At the top of the packet list, you can see a few LDAP search packets. This gives me an idea of what kind of workload the domain controller is receiving, where it's coming from, and so forth. If I know a domain controller is overloaded, this can be the start of the process to discover where the workload is originating—in this case, it might be a new application submitting poorlyconstructed LDAP queries to the directory.
System Center Operations Manager
System Center Operations Manager is Microsoft's commercial offering for monitoring both performance and functionality in AD as well as in numerous other Microsoft products and Windows subsystems. SCOM, as it's affectionately known, utilizes both performance counters and other data feeds much as Windows' native tools do. What sets SCOM apart are two things:
- Data is stored for a long period of time, enabling trending and other historical tasks
- Data is compared with a set of Microsoft‐provided thresholds, packaged into Management Packs, that tell you when data represents a good, bad, or "going bad" condition
That last bit enables SCOM to more proactively alert you to performance conditions that are trending bad, and to then show you detailed real‐time and historical data to help troubleshoot the problem. In many cases, Management Packs can include prescriptive advice for failure conditions, helping you to troubleshoot and solve problems more rapidly. As a tool, SCOM addresses most, if not all, of the weaknesses in the native Windows toolset. It does so by relying primarily on native technologies, and it does so in a way that often imposes less monitoring overhead than some of the native tools. Having SCOM collect performance data for a month, for example, is a lot easier on the monitored server than running Performance Monitor continuously on that server. SCOM does, however, require its own infrastructure of servers and other dependencies, so it adds some complexity to your environment.
Unfortunately, one of SCOM's greatest strengths—its ability to monitor a wide variety of products and technologies from a single console—is also a kind of weakness because it doesn't offer a lot of technology‐specific functionality. For example, SCOM isn't a great way to construct an AD replication topology map because that's a very AD‐specific capability that wouldn't be used by any other product. In other words, SCOM is a bit generic. Although it can provide great information, and good prescriptive advice, it isn't necessarily the only tool you'll need to troubleshoot every problem. SCOM can alert you to most types of problems (such as an unacceptably high number of replication failures), but it can't always help you visualize the underlying data in the most helpful way.
Third‐Party Tools to Consider
I'm not normally a fan of pitching third‐party products, and I'm not really going to do so here. That said, we've identified some weaknesses in the native tools provided with Windows. Some of those weaknesses are addressed by SCOM, but because that tool itself is a commercial add‐on (that is, it doesn't come free with Windows), you owe it to yourself to consider other add‐on commercial tools that might address the native tools' weaknesses in other ways, or perhaps at a different price point. That said, what are some of the weaknesses that we're trying to address?
Weaknesses of the Native Tools
Although I think Microsoft has provided some great underlying technologies in things like event logs and performance counters, the tools they provide to work with those are pretty basic. In order to decide if a replacement tool is suitable, we need to see if it can correct these weaknesses:
- Non‐centralized—Windows' tools are per‐server, and when you're talking about AD, you're talking about an inherently distributed system than functions as a single, complicated unit. We need tools that can bring diagnostic and performance information together into a single place.
- Raw data—Windows' tools really just provide GUI access to underlying raw data, either in the form of events or performance counters or whatever. That's really suboptimal. What we want is something to translate that data into English, tell us what it means, and possibly provide intelligence around it—which is a lot of what SCOM offers, really.
- Limited data—Windows' tools collect the information available to them through native diagnostic and performance technologies—and that's it. There are certainly instances when we might want more data, especially more‐specific data that deals with AD and its unique issues.
- Generic—Windows' tools are pretty generic. The Event Viewer and Performance Monitor, for example, aren't AD‐specific. But an AD‐specific tool could go a long way in making both monitoring and troubleshooting easier because it could present information in a very AD‐centric fashion.
Ways to Address Native Weaknesses
There are a few ways that vendors work to address these weaknesses:
- Centralization—Bringing data together into one place is almost the first thing any vendor seeks to address when building a toolset. Even Microsoft did this with SCOM.
- Intelligence—Translating raw data into processed information—telling us if something is "good" or "bad," for example—is one way a tool can add a great deal of value. Prescriptive advice, such as providing advice on what a particular event ID means and what to do about it, is also useful. This kind of built‐in "knowledge base" is a major selling point for some tool sets.
- More data—Some tools either supplement or bypass the native data stores and collect more‐detailed data straight from the source. This might involve tapping into LDAP APIs, AD's internal APIs, and so forth.
- Task‐specific—Tools that are specifically designed to address AD monitoring can often do so in a much more helpful way than a generic tool can. Replication topology maps, data flow dashboards, and so forth all help us focus on AD's specific issues.
Vendors in this Space
There are a lot of players in this space. A lot a lot. Some of the major names include:
- Quest
- ManageEngine
- Microsoft
- Blackbird Management Group
- NetIQ
- IBM
- NetPro (which was purchased by Quest)
Most of these vendors offer tools that address native weaknesses in a variety of ways. Some utilize underlying native technologies (event logs, performance counters, and so forth) but gather, store, and present the data in different ways. Others bypass these native technologies entirely, instead plugging directly into AD's internals to gather a greater amount of information, different information, and so forth.
In addition, there are a number of smaller tools out there that have been produced by the broader IT community and smaller vendors. A search engine is a good way to identify these, especially if you have specific keywords (like "replication troubleshooting") that you can punch into that search engine.
AD LDS
Chapter 7 gives me an opportunity to cover additional information: AD's smaller cousin, Active Directory Lightweight Directory Services (AD LDS). We'll look at what it is, when to use it, when not to use it, and how to troubleshoot and audit this valuable service.
Active Directory Troubleshooting: Tools and Practices
For the most part, in most organizations, Active Directory (AD) "just works." Over the past 10 years or so, Microsoft has improved both AD's performance and its stability, to the point where few organizations with a well‐designed AD infrastructure experience day‐to‐day issues. That said, when things do go wrong, it can be pretty scary because a lot of us don't have day‐to‐day experience in troubleshooting AD. The goal of this chapter is to provide a structured approach to troubleshooting to help you put out those fires faster.
For this chapter, I'll be drawing a lot on the wisdom and experience of Sean Deuby, a fellow Microsoft Most Valuable Professional award recipient and a real AD troubleshooting guru. You might enjoy reading his infrequently‐updated blog at http://www.windowsitpro.com/blogs/ActiveDirectoryTroubleshootingTipsandTricks.aspx. Although he doesn't post a lot, what he does post is worth the trip.
Narrowing Down the Problem Domain
"How do you find a wolf in Siberia?" It's a question I and others have used to kick off any discussion on troubleshooting. Siberia is, of course, a huge place, and finding a particular anything—let alone a wolf—is tough. The answer to the riddle is a maxim for troubleshooting:
Build a wolf‐proof fence down the center, and then look on one side of the fence.
Troubleshooting consists mainly of tests, designed to see if a particular root cause is responsible for your problems. The answer to the riddle provides important guidance: Make sure your tests (that is, the wolf‐proof fence) can definitively eliminate one or more root causes (that is, one whole half of Siberia). Don't bother conducting tests that can't eliminate a root cause. For example, if a user can't log in, you might first check their physical network connection. Doing so definitively eliminates a potential problem (network connectivity) so that you can move on to other possible root causes. Of course, checking connectivity only eliminates one or two possible root causes; a better first test would eliminate a whole host of them. For example, checking to see whether a different user could log in might eliminate the vast majority of potential infrastructure problems, making that a better wolf‐proof fence.
Sean's Seven Principles for Better Troubleshooting
Here's where I'll repeat excellent advice Sean Deuby once offered. Follow these seven principles (which I'll explain through the filter of my own experience) and you'll be a faster, better troubleshooter in any circumstance.
- Be Logical. Pay attention to how you're attempting to solve the problem. Before you do anything, ask yourself, "What outcome do I expect from this? If I get that outcome, what does it mean? If I don't get the expected outcome, what does that mean?" Don't do anything unless you know why, and unless you can state what the follow‐up step would be.
- Remember Occam's Razor. Simply put, the simplest solution is often the correct one. Don't start rebooting domain controllers until you've checked that the user is trying the correct password.
- What Changed? If everything was working fine an hour ago, what's different? This is where change auditing tools can come in handy. Although I don't specifically recommend it, I've used Quest's ChangeAuditor for Active Directory in the past because it keeps a very detailed, real‐time log of changes, and it's been a big help in solving some tricky issues. Whatever changed recently is a very likely candidate for being the root cause of your current woes.
- Don't Make Assumptions. It's easy to make assumptions, but sticking with an orderly elimination of possible causes will get you to the root cause of the problem more consistently. For example, don't assume that just because one user can log on that everything's okay with the infrastructure; the problem user might be hitting a different domain controller, for example.
- Change One Thing at a Time, and Retest. You won't get anywhere with five people attacking the problem, each one changing things as they go. You also won't get anywhere if you're changing multiple things at once. If the boss is tearing his hair out to get things fixed, remind him that you have just as much capability to further break things if you're not methodical.
- Trust, but Verify, Evidence. Sometimes an inaccurate problem description can get you going in the wrong direction—so verify everything (this goes back to not making assumptions, too). "I can't log in!" a user cries over the phone. "Log into what?" you should ask, before diving into AD problems. Maybe the user is talking about their Gmail account.
- Document Everything You Try. Especially for tough issues, documenting everything you try will help keep you from repeating steps, and will help you eliminate possible causes more easily. It's also crucial in the inevitable post‐mortem, where you and your colleagues will discuss how to keep this from happening again, or how to solve it more quickly the next time.
A Flowchart for AD Troubleshooting
Sean has further helped by coming up with an AD troubleshooting flowchart, which I'll reprint in pieces throughout this chapter. You should check Sean's blog or Web site (which is shown at the bottom of the chart pages) for the latest revision of the flowchart. Sean's blog also offers a full‐sized PDF version, which I keep right near my desk at all times. The flowchart starts with that is shown in Figure 3.1, which is the core starting point that gets you off to the different sections of the chart.
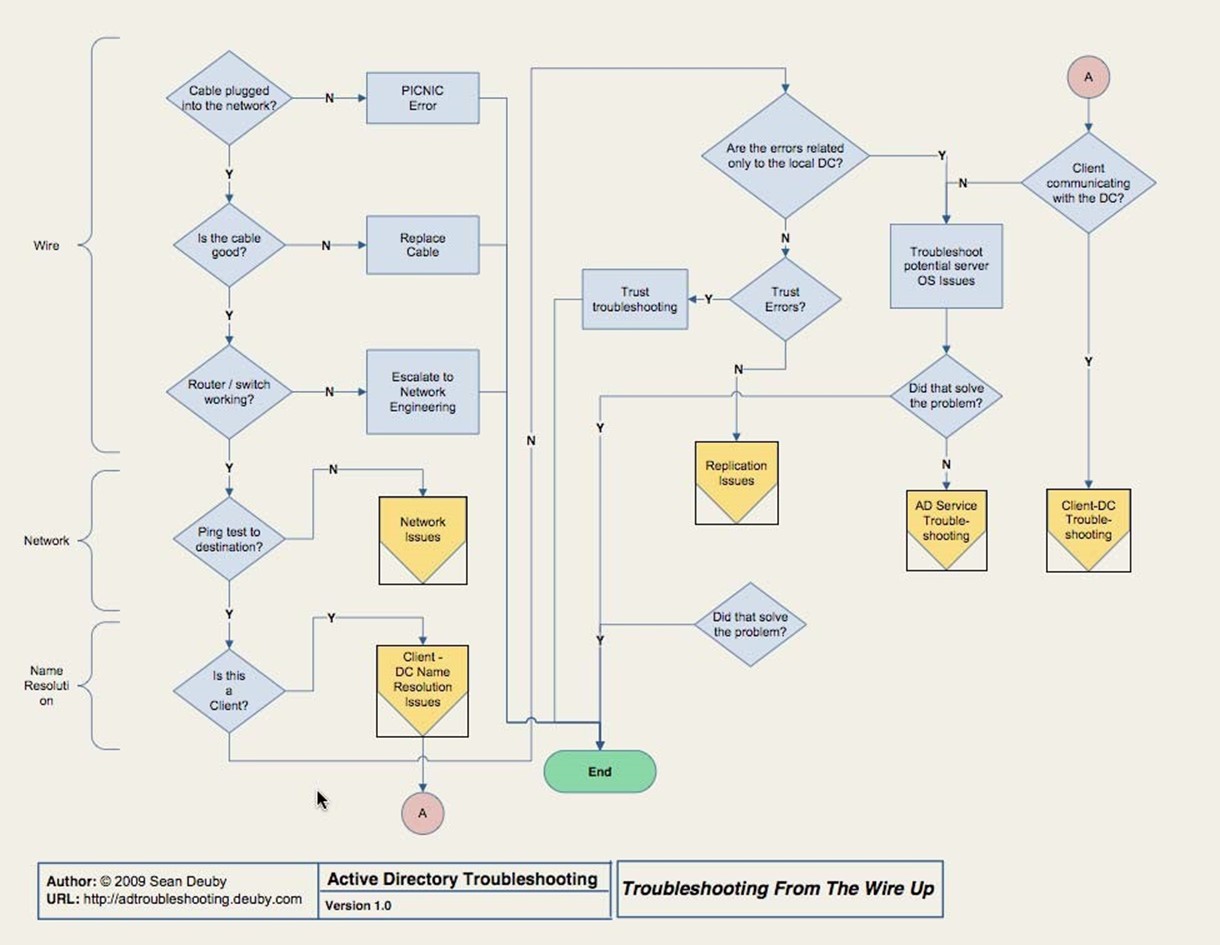
Figure 3.1: Starting point in AD troubleshooting.
I strongly recommend that you head over to Sean's blog or Web site to download the PDF version of this flowchart for yourself. You may find a later version, which is great—it'll still start off in basically this same way.
Start in the upper‐left, with "Cable plugged into network?" and work down from there. The basics—the "wire" portion—should be things you can quickly eliminate, but don't eliminate them without actually testing them. You might, for example, attempt to ping a known‐good IP address on the network (using an IP address prevents potential DNS issues from becoming involved at this point). If that doesn't work, you've got a hardware issue of some kind to solve.
Easy Stuff: Network Issues
A ping does, of course, start to encroach on the "Network" section of the flowchart. Stick with IP addresses to this point because we're not ready to involve DNS yet. If the ping isn't successful, and you've verified the network adapter, cabling, router, and other infrastructure hardware, you're ready to move on to Figure 3.2, which is the Network Issues portion of the flowchart.
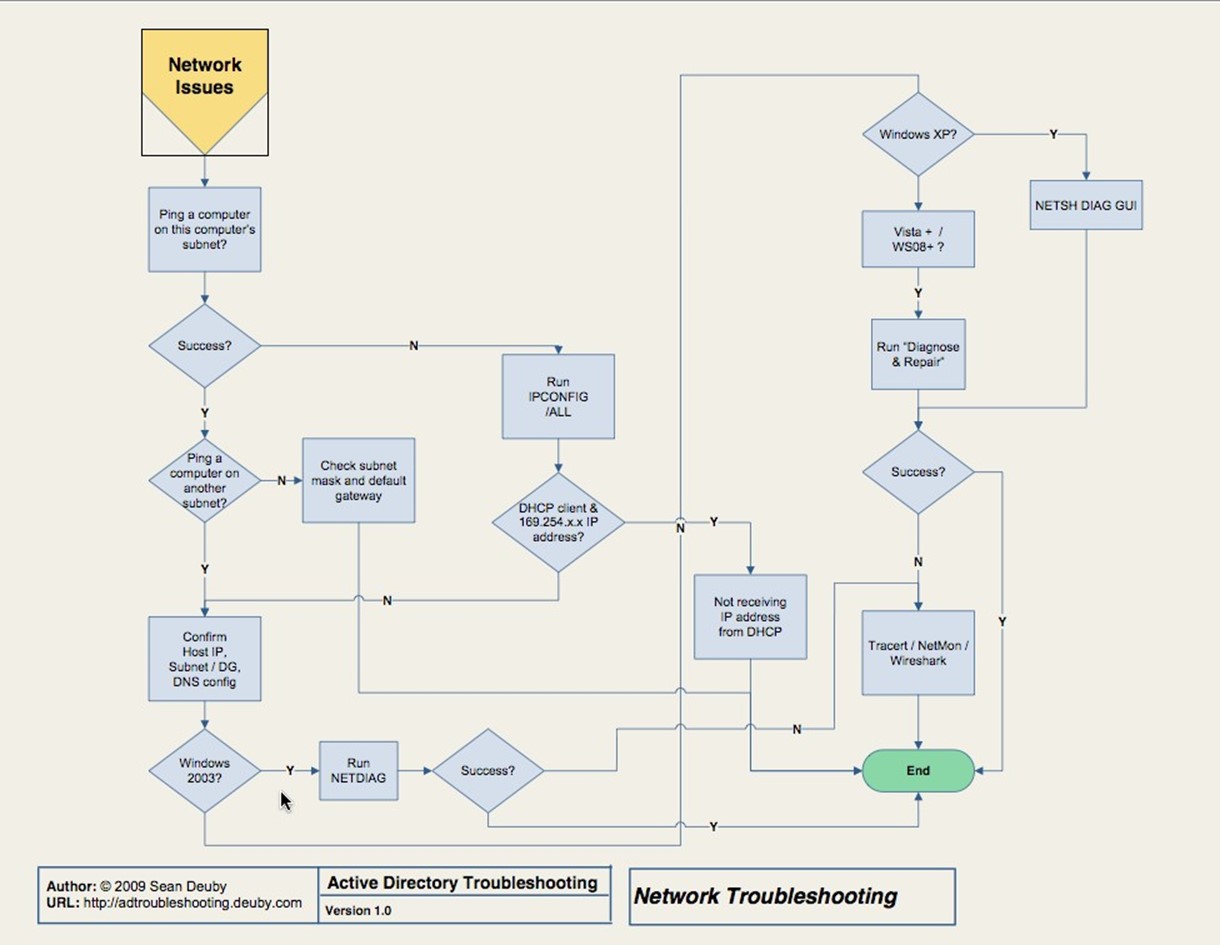
Figure 3.2: Network issues.
The tools here are straightforward, so I won't dwell on them. You'll be using ping, Ipconfig, Netdiag, and other built‐in tools. At worst, you might find yourself hauling out Wireshark or Network Monitor to actually check network packets. That's not truly AD troubleshooting, so it's out of scope for this book, but the flowchart should walk you through to a solution if this is your root cause.
Name Resolution Issues
If a ping to a different intranet subnet worked by IP address, it's time to start pinging by computer name to test name resolution. Watch the ping command's output to see if it resolves a server's name to the correct IP address. Ideally, use the name of a domain controller or two because we're testing AD problems. If ping doesn't resolve correctly, or can't resolve at all, you're ready to move into the name resolution issues.
The "Client‐DC Name Resolution Issues" flowchart is designed for when you're troubleshooting connectivity from a client to a domain controller; if you're troubleshooting problems on a server, you'll skip this step and move on in the core flowchart (Figure 3.1). If you are on a client, the flowchart that Figure 3.3 shows will come into play.
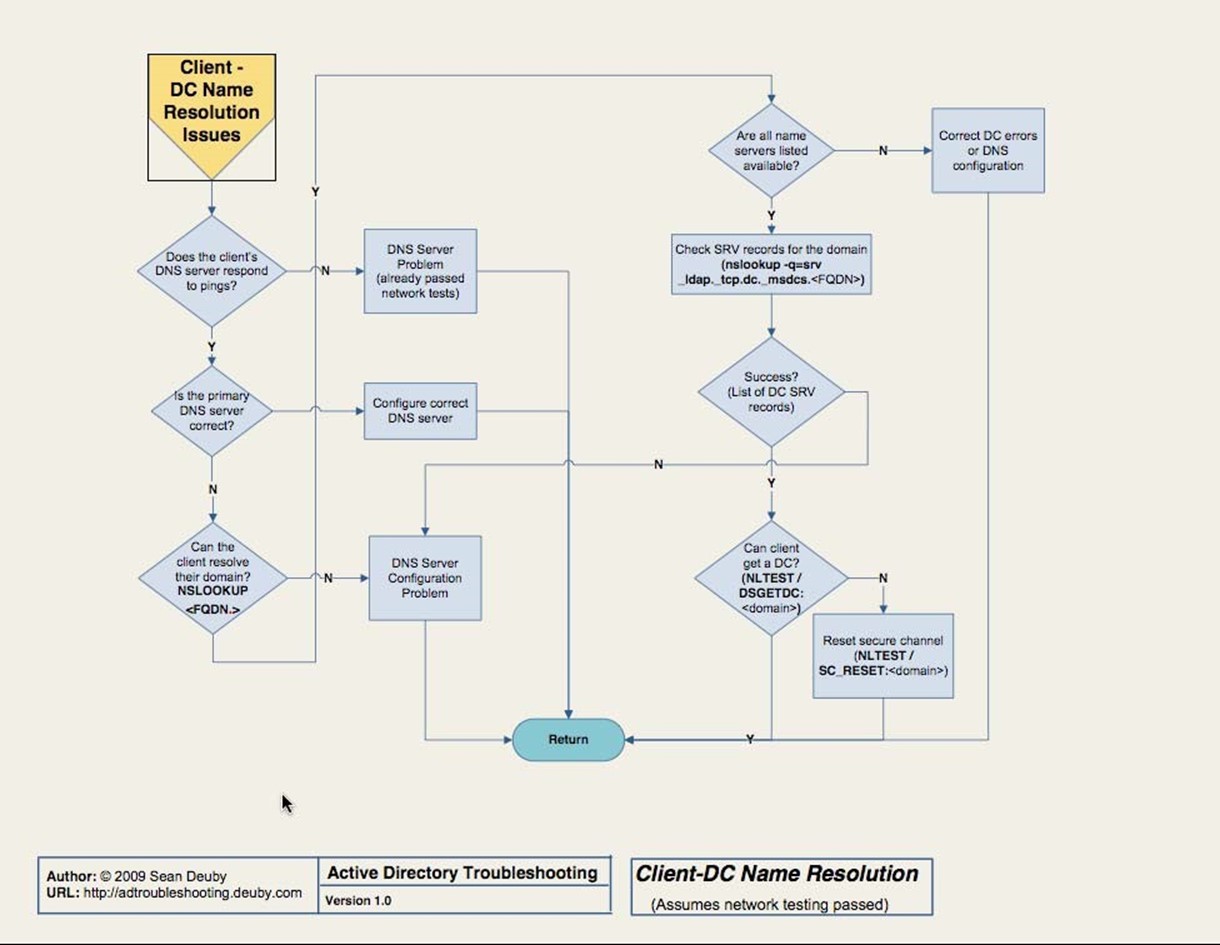
Figure 3.3 ClientDC name resolution issues.
Again, the tools for troubleshooting name resolution should be familiar to you. Primarily, you'll rely on ping and Nslookup. Of these, Nslookup might be the one you use the least— but if you're going to be troubleshooting AD, it's worth your while to get comfortable with it. The flowchart offers the exact commands you need to use, provided you know the FullyQualified Distinguished Name (FQDN) of your domain (for example, dc=Microsoft,dc=com for the Microsoft.com domain).
The other tool you'll find yourself using is Nltest, which permits you to test the client's ability to connect to a domain controller, among other things.
Log Spelunking
Once name resolution is resolved, or if it isn't the problem, you have a bit of checking to do before you move on. Specifically, you're going to have to look in the System and Application event logs on the domain controllers in the client's local site (or whatever domain controller you're having a problem with, if it's just a specific one). If you find any errors, you'll have to resolve them—and they may be more specific to Windows than to AD. Don't ignore anything. In fact, that "don't ignore anything" is a huge reason I hate domain controllers that do anything other than run AD, and perhaps DNS and DHCP. I once had a domain controller that was having real issues talking to the network. There were a bunch of IIS‐related errors in the log, but I ignored those—what does IIS have to do with networking or AD, after all? I shouldn't have made assumptions: It turned out that IIS was more or less jamming up the network pipe. Shutting it down solved the problem for AD.
Having to dig through the event logs on more than one domain controller— heck, even doing it on one server—is time‐consuming and frustrating. This is where some kind of log consolidation and analysis tool can help tremendously. Get all your logs into one place, and have software that can pre‐filter the event entries to just those that need your attention. Software like Microsoft System Center Operations Manager can also help because one of its jobs is to scan event logs and call to your attention any events that require it.
If you don't see any errors specific to the domain controller or controllers, you move on. You're looking first for errors related to trusts, and if you find any, you'll need to resolve them. If you did find errors related to the domain controller or controllers, and you corrected them but that didn't solve the problem, you're moving on to AD service issues.
AD Service Issues
Figure 3.4 contains the AD service issue portion of the troubleshooting flowchart. Here, we've moved into the complex part of AD troubleshooting. First, of course, look in the event log for errors or warnings. Don't ignore something just because you don't understand it; you're going to have to amass knowledge about obscure AD events so that you know which ones can be safely ignored in a given situation.
This is where knowledge, more than pure data, comes in handy. Operations Manager, for example, can be extended with Management Packs that should be called Knowledge Packs. When important events pop up in the log, Ops Manager can not only alert you to them but also explain what they mean and what you can do to resolve them. NetPro made a product called DirectoryTroubleshooter that went even further, incorporating a complete knowledge base of what those events meant and how to deal with them. Sadly, the product was discontinued when the company was purchased by Quest, but Quest does offer a similar product: Spotlight on Active Directory. Again, its job is to call your attention to problematic events and provide guidance on how to resolve them.
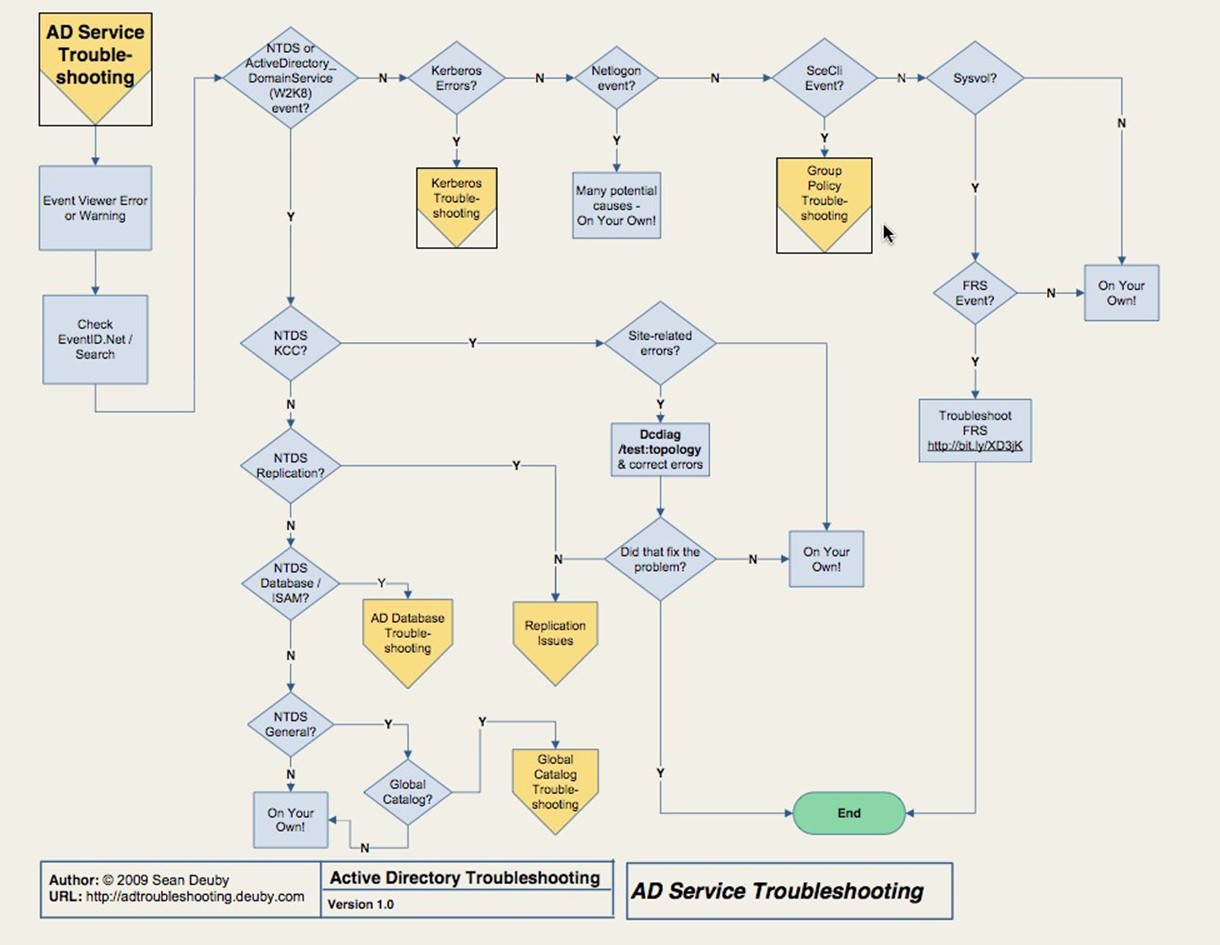
Figure 3.4: AD service troubleshooting.
The remainder of the AD service troubleshooting flowchart helps you narrow down the potential specific AD service involved in the problem based on the error messages you find in the log. You might be looking at Kerberos, the AD database, Global Catalog (GC), Replication, or Group Policy. Along the way, you'll also troubleshoot site‐related issues and the File Replication System (FRS). We'll pick up most of these major service issues in dedicated sections later in this chapter.
Client‐Domain Controller Issues
Assuming you resolved any client name resolution issues earlier, if you're still having problems with the client communicating with the domain controller, you'll move to the
Client‐DC Troubleshooting chart, which Figure 3.5 shows.
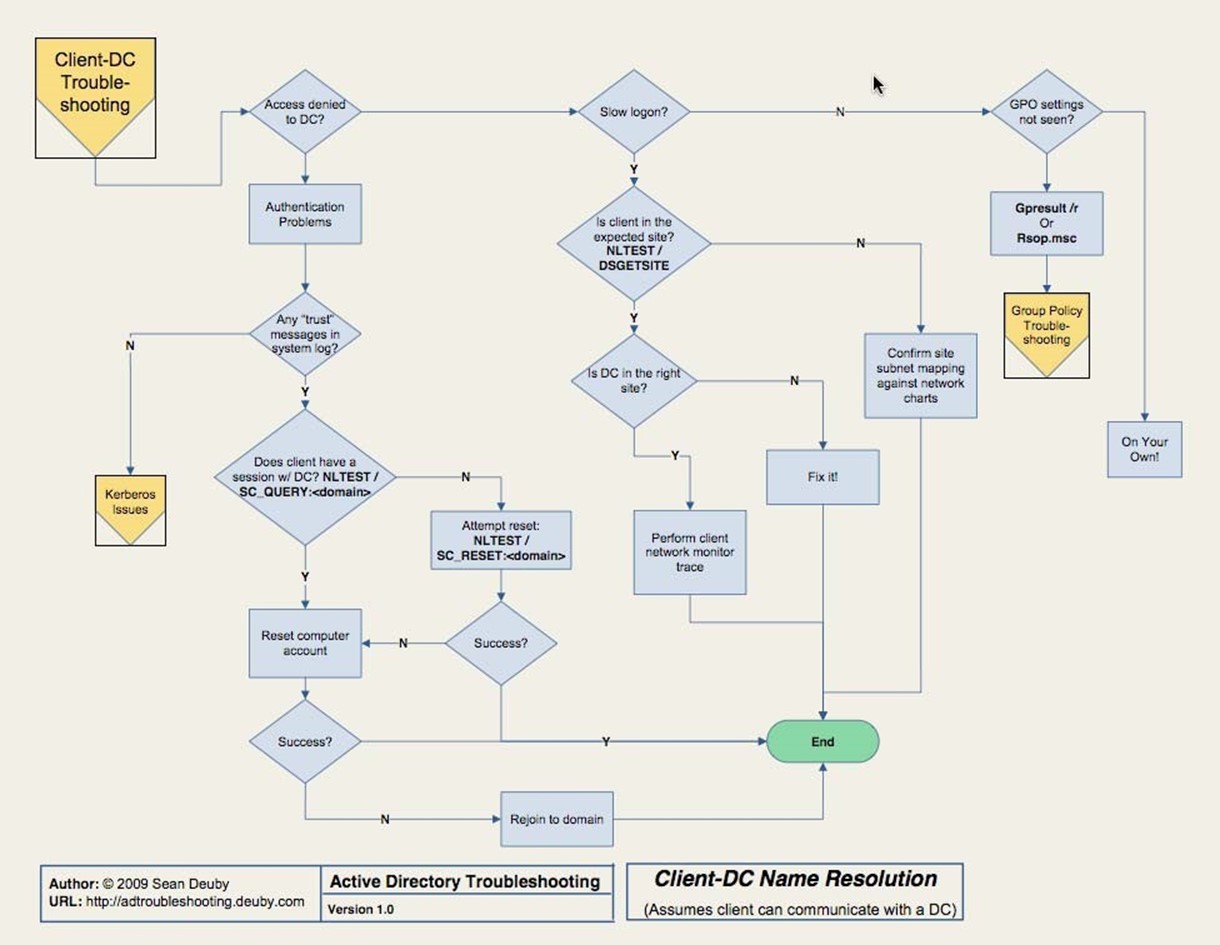
Figure 3.5: ClientDC troubleshooting.
Here, you'll have to personally observe symptoms. For example, are you getting "Access Denied" errors on the client, or does logon seem unusually slow for the time of day? Are you logging on but not getting Group Policy Object (GPO) settings applied? You'll rely heavily on Nltest to verify client‐domain controller connectivity and communications; you could wind up dealing with Kerberos issues, which we'll come to later in this chapter.
This is also the point where you're going to want a chart of your network so that you can confirm which domain controllers should be in which sites. You'll want that chart to also list each subnet that belongs to each site. You have to verify that reality matches the desired configuration, and don't skip any steps. It seems obvious to assume that a client was given a proper address by DHCP and is therefore in the same site; don't ever make that assumption. I once had a client that seemed to be working just fine but was in fact hanging onto an outdated IP address, making the client believe it was in a different site. The way our LAN was configured, the incorrect IP address was still able to function (we used a lot of VLAN stuff and IP addressing got incredibly confusing), but the client didn't see itself as being in the proper site—so it wouldn't talk to the right domain controller.
Replication Issues
If the flowchart has gotten you to this point, we're dealing with the page Figure 3.6 shows.
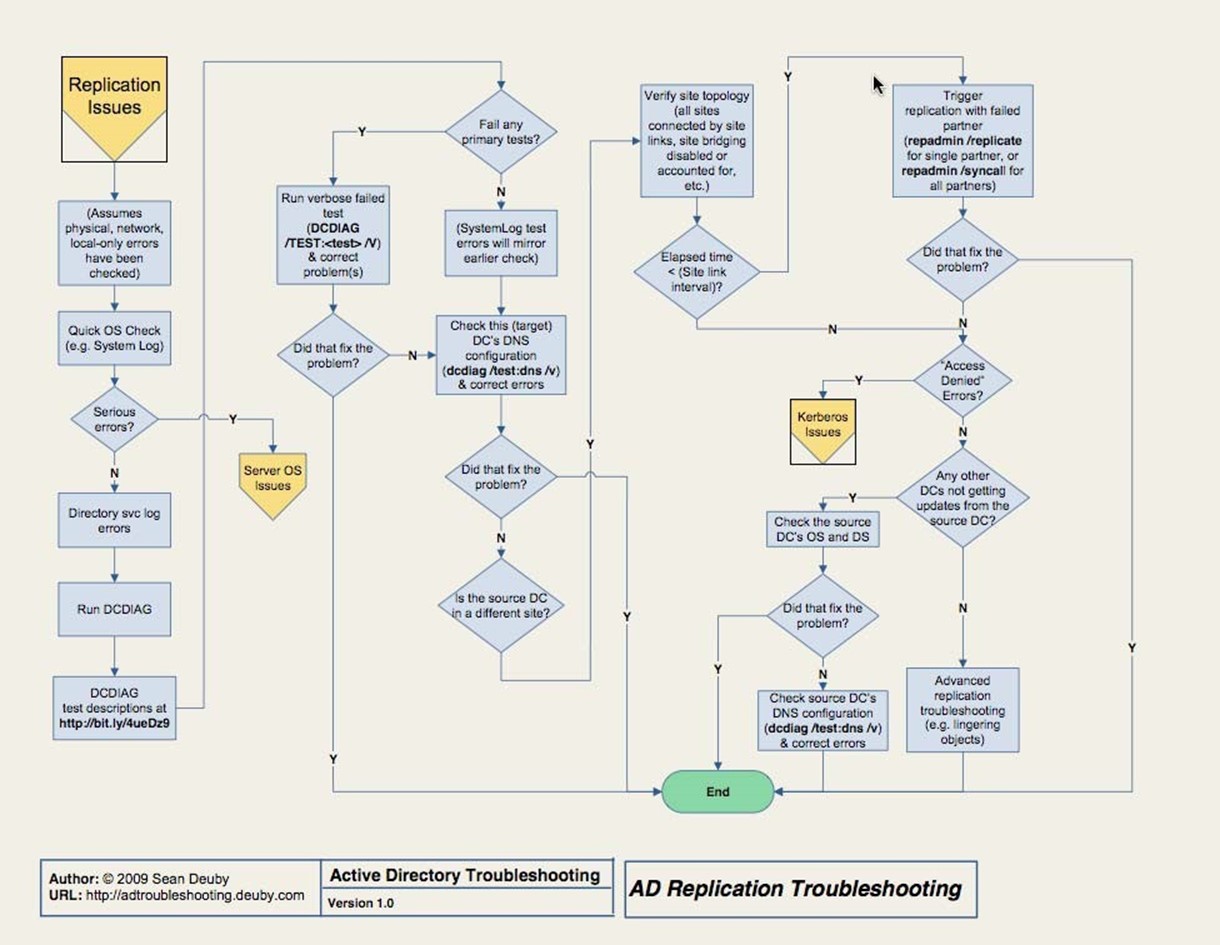
Figure 3.6: Replication issues.
Troubleshooting AD replication is often perceived as the most difficult and mysterious thing you can do with AD. It's like magic: either the trick works or it doesn't, and you'll never know why either way. I see more people struggle with replication issues than with anything else, yet replication is the one thing that can come up most frequently, due in large part to its heavy reliance on proper configuration and the underlying network infrastructure.
Sean proposes four reasons, which I agree with, that make replication troubleshooting difficult for people. In my words, they are:
- They've not been trained in a formal troubleshooting methodology. More admins than you might believe tend to troubleshoot by rote, meaning they try the same things in the same order every time—which is good—without really understanding what they're testing—which is bad.
- They don't approach the problem logically. Think about what's happening. Does it make sense to test name resolution between two domain controllers when other communications between them seem unhindered?
- They don't understand how replication works. This, I think, is the biggest problem. If you don't understand what's happening under the hood, you have no means of isolating individual processes or components to test them. If you can't do that, you can't find the problem.
- They don't understand what the tools do. This is also a big problem because if you don't really know what's being tested, you don't know how to eliminate potential root causes from your list of suspects.
Ultimately, you can't just run tools in the order someone else has prescribed. Sean proposes four te s ps to help proceed; I prefer to limit the list to three:
- Form a hypothesis. What do you think the problem is? A firewall rule? IP addressing problem? DNS problem? Apply whatever experience you have to just pick a problem that seems likely.
- Predict what will happen. In other words, if you think external communications might be failing, you might predict that internal communications will be fine.
- Test your prediction. Use a tool to see if you're right. If you are, you've narrowed the problem domain. If you're not, you form a new hypothesis.
If you remember science class from elementary school, you might recognize this as the scientific method, and it works as well for troubleshooting as it does for any science.
Replication troubleshooting cannot proceed unless you've already resolved networking, local‐only issues, and other problems that precede this step in the core flowchart. Once you've done that, you'll find yourself quickly looking for OS‐related issues in the event log, then move on to the Dcdiag tool—the flowchart provides a URL with a description of the tests to run.
You'll also have to exercise human review and analysis. Do your site links, for example, match your big network chart printout? In other words, are things configured as they should be? This is where a change‐auditing tool can save a ton of time. Rather than manually checking to make sure all your sites, site links, and other replication‐related configurations are right, you could just check an audit log to determine whether anything's changed. In fact, some change‐auditing tools will alert you when key changes happen—like site link reconfigurations—so that you can jump on the problem before it becomes an issue in the environment.
AD Database Issues
Next, you'll move into troubleshooting the AD database, which is covered in the flowchart that Figure 3.7 shows.
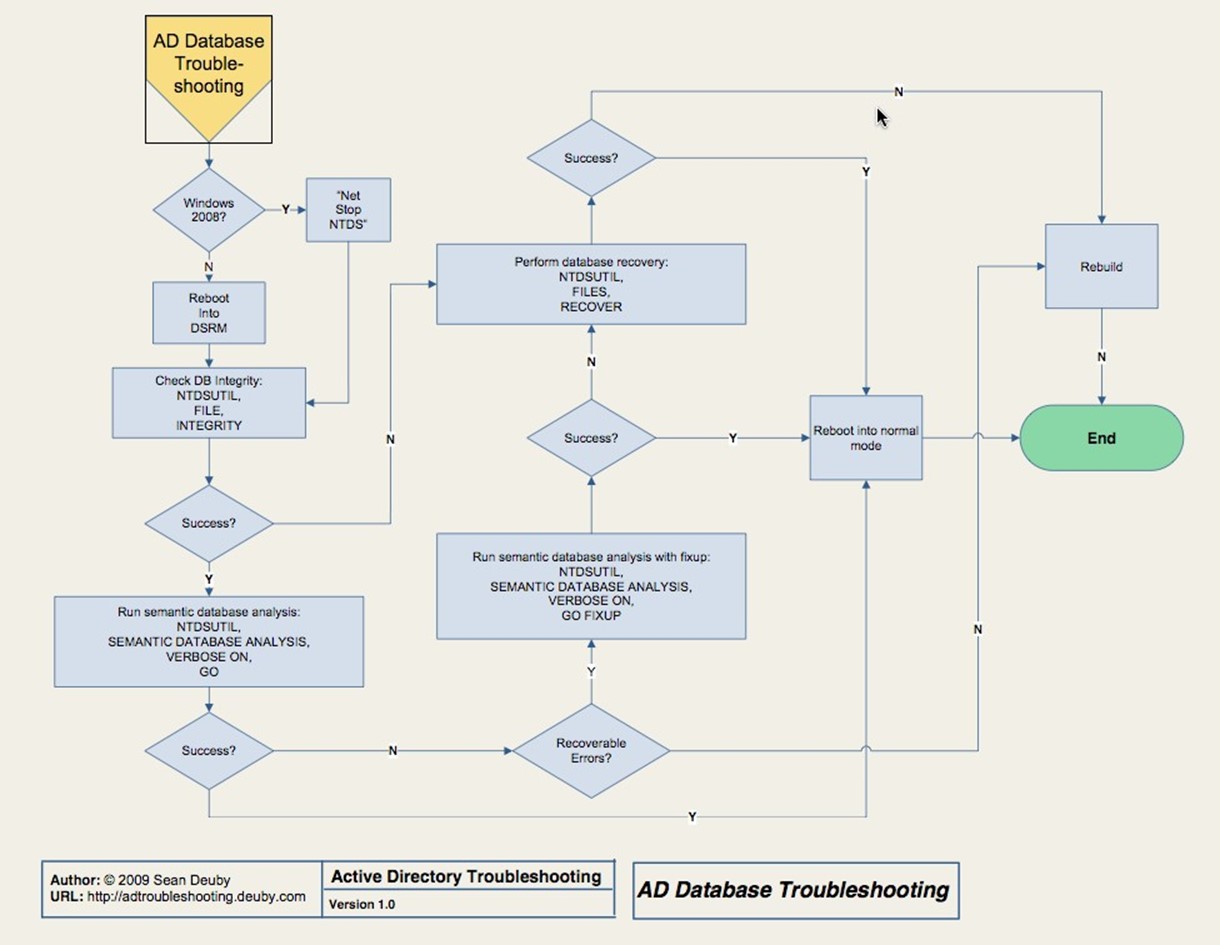
Figure 3.7: AD database troubleshooting.
Here, you'll probably be taking a domain controller offline so that you can reboot into Directory Services Restore Mode (DSRM)—make sure you know the DSRM password for whatever domain controller you're dealing with. You'll use NTDSUTIL to check the file integrity of the AD database itself because, at this point, we're starting to suspect corruption of some kind. If you find it, you'll be doing a database restore. If you don't have a backup, you're probably looking at demoting and re‐promoting the domain controller, if not rebuilding the serve entirely. Sorry.
Again, this is where third‐party tools can help. You may have thought that the "AD Recycle Bin" feature of Windows Server 2008 R2 was a great feature, but it isn't designed to deal with a total database failure. Third‐party recovery tools (which are available from numerous vendors) can get you out of a jam here. Make sure you're not using too old a backup; ideally, domain controller backups shouldn't be older than a few days. Older backups will require the domain controller to perform a lot more replication when it comes back online, and a very old backup can re‐introduce tombstoned (deleted) objects to the domain, which would be a Bad Thing.
Group Policy Issues
If you've made it this far, AD's most complex components are working, and you're on to troubleshooting one of the easier elements. First, recognize that there are two broad classes of problem with Group Policy: no settings from a Group Policy object are being applied or the wrong settings are being applied. This chapter, as shown in the flowchart in Figure 3.8, is concerned only with the former. If you're getting settings but not the right ones, you need to dive into the GPOs, Resultant Set of Policy (RSoP), and other tools to discover where the wrong settings are being defined.
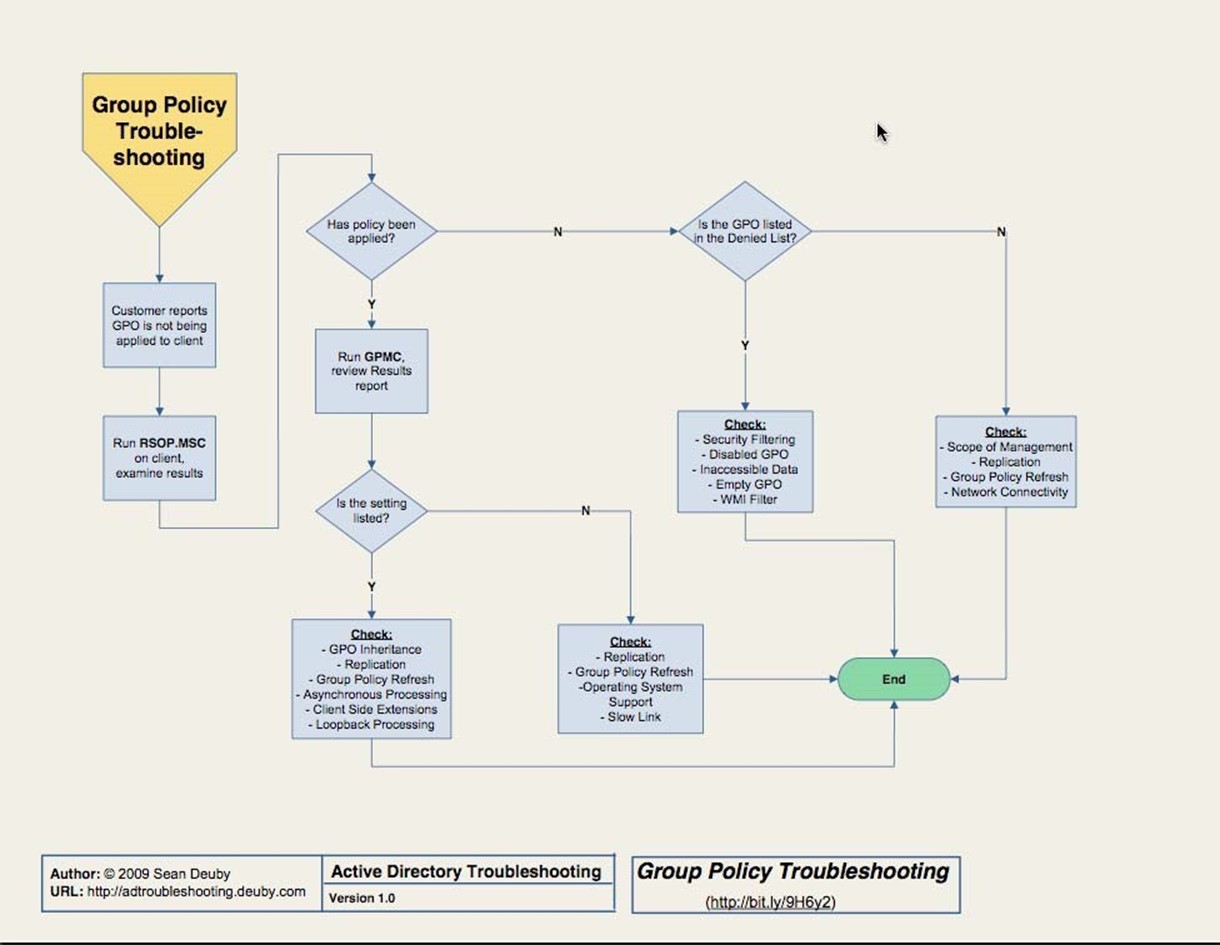
Figure 3.8: Group Policy troubleshooting.
Troubleshooting GPOs is pretty much about verifying their configuration. If a user isn't getting a specific GPO, the problem will be due to replication, inheritance, asynchronous processing (which means they're getting the GPO, just not as quickly as you expected), and so forth. Group Policy is complicated, and knowing all the little tricks and gotchas is key to solving problems. I recommend buying Jeremy Moskowitz' latest book on the subject; he's pretty much the industry expert on Group Policy and his books comes with great explanations and flowcharts to help you troubleshoot these problems.
Unraveling "what's changed" is also the easiest way to fix GPO problems. Unfortunately, most tools that track AD configuration changes don't touch GPOs because GPOs aren't stored in AD itself. There are tools that can place GPOs under version‐control, and can help track the changes related to GPOs that do live in AD (such as where the GPOs are linked). Quest, NetWrix, Blackbird Group, and NetIQ all offer various solutions in these spaces.
Kerberos Issues
Finally, the last area we'll cover is Kerberos. Figure 3.9 shows the last page in the flowchart.

Figure 3.9: Kerberos issues.
Here, you'll need to install resource kit tools, preferably Kerbtray.exe, so that you can get a peek inside Kerberos. You'll also need a strong understanding of how Kerberos works.
Here's a brief breakdown:
- When you log on, you get a Ticket‐Granting Ticket (TGT) from your authenticating domain controller. This enables you to get Kerberos tickets, which provide access to a specific server's resources. Each server you access will require you to have a ticket for that server. So each time you access a new server every day, you'll have to first contact a domain controller to get that ticket.
- Ticket validity is controlled by time stamps. Every machine in the domain needs to have roughly the same idea of what time it is, which is why Windows automatically synchronizes time within the domain. A skew of about 5 minutes is allowed by default.
- Tickets are a bit sensitive to UDP fragmentation, meaning you need to look at your network infrastructure and make sure it isn't hacking UDP packets into fragments. You can also force Kerberos to use TCP, which is designed to handle fragmentation.
There are a few other uncommon issues also covered by the flowchart.
Active Directory Security
In the security world, AAA is usually the term used to describe the broad functionality of security: authentication, authorization, and auditing. For a Windows‐centric network, Active Directory (AD) serves one of those roles: authentication. Internally, AD also has authorization and auditing functionality, which are used to secure and monitor objects listed within the directory itself. In this chapter, we'll talk about all of these functions, how AD implements them, and some of the pros and cons of AD's security model. We'll also look at reasons your own security design might be due for a review, and potentially a remodel.
This chapter will also discuss security capabilities usually acquired from third parties. I know, it would be nice to think that AD is completely self‐contained and capable of doing everything we need from a security perspective. In a modern business world, however, that's rarely true, as we shall see.
Active Directory Security Architecture
As mentioned, AD has a role in each of the three main security functions. Let's take each one separately.
Authentication: Kerberos
Microsoft adopted an extended version of the industry‐standard Kerberos protocol for use within AD. Compared with Microsoft's older authentication protocol, NTLM, Kerberos provides distinct benefits:
- Mutual authentication. Both sides of any security transaction are identified and authenticated to each other. With NTLM, the client was authenticated, but the client wasn't able to verify the server's identity.
- Distributed processing. Clients are responsible for maintaining 100% of the information needed to authenticate themselves to a server; servers maintain nothing. That behavior reduces server overhead, improving overall performance.
- Secure. Unlike NTLM, Kerberos doesn't transmit any portion of your password over the network at any time—not even in encrypted form. Thus, passwords remain a bit safer.
The name Kerberos comes from Greek mythology, and identifies the mythical three‐headed dog that guarded the gates to the Underworld. The threeheaded bit is the important one because the protocol entails three parties: the client, the server, and the Key Distribution Center (KDC).
In AD, Kerberos relies on the fact that the KDCs—a role played by domain controllers— have access to a hashed version of every user and computer password. The users and computers, of course, know their passwords, and the computers (which users log on to, of course) know the same password‐hashing algorithm as the domain controllers. This setup enables the hashed passwords to be used as a symmetric encryption key: If the KDC encrypts something with a user or computer password as the encryption key, that user or computer will be able to decrypt it using the same hashed password.
When a user logs on, their computer—on the user's behalf—contacts the KDC and sends an authentication packet. The KDC attempts to decrypt it using the user's hashed password, and if that is successful, the KDC can read the authentication packet. The KDC constructs a ticketgranting ticket (TGT), encrypting it first with its own encryption key (which the user doesn't know), then again with the user's key (which the user does know). The user's computer stores this TGT in a special area of memory that isn't swapped to disk at any time, so the TGT is never permanently stored. The TGT contains the user's security token, listing all of the security identifiers (SIDs) for the user and whatever groups they belong to.
When the user needs to access a server, their computer resends the TGT to a domain controller. The domain controller decrypts the TGT using its private key—keep in mind that there's no way the user could have tampered with the TGT and still have that decryption work because the user doesn't have access to the domain controller's private key. The KDC creates a copy of the TGT called a ticket, and encrypts it using the hashed password of whatever server the user is attempting to access. That's encrypted again using the user's key, and sent to the user. The user then transmits that ticket to the server they want to access, along with a request for whatever resource they need.
The server attempts to use its key to decrypt the ticket. If it's able to do so, then several things are known:
- The server is the one the user intended, because if it weren't, it wouldn't have the key needed to decrypt and read the ticket.
- The user's identity is known, because it's included in a ticket that only the server could read.
- The user's identify is trusted because the ticket was encrypted not by the user but by the KDC, and in a way that only the KDC and the server could read.
Figure 4.1 shows a functional diagram of how Kerberos works. Keep in mind that this isn't a Microsoft‐specific protocol; Microsoft made some extensions to allow for Windowsspecific needs—such as the need to include a security token in the tickets—but Windows'
Kerberos still works like the standard MIT‐developed protocol.
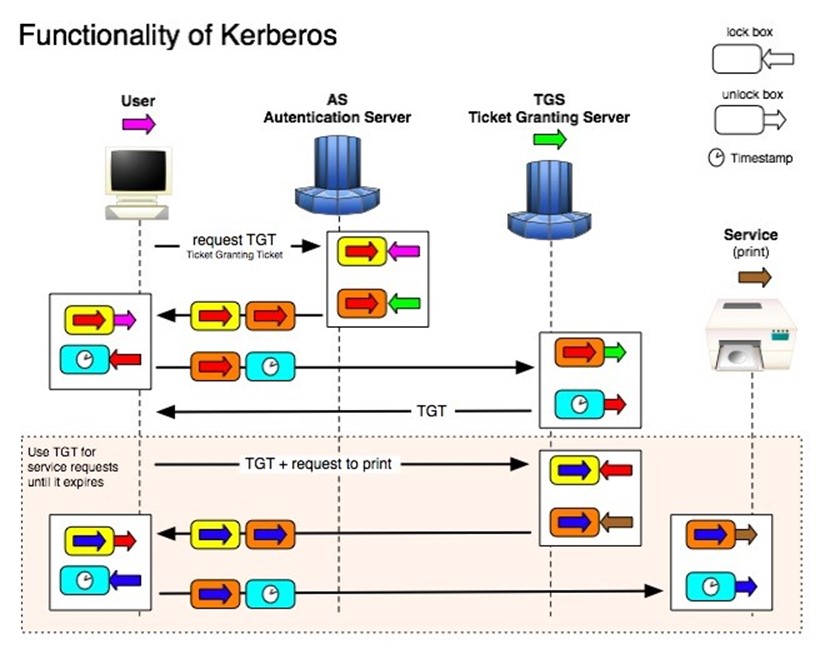
Figure 4.1: Kerberos functional diagram.
The user's computer caches the ticket for 8 hours (by default), enabling it to continue accessing that server over the course of a work day.
If a user's group memberships are changed during the day, that change won't be reflected until the user logs off—destroying their tickets and TGT—and logs back on—forcing the KDC to construct a new TGT.
Microsoft provides a utility called KerbTray.exe, shown in Figure 4.2, which provides a way to view locally‐cached tickets.
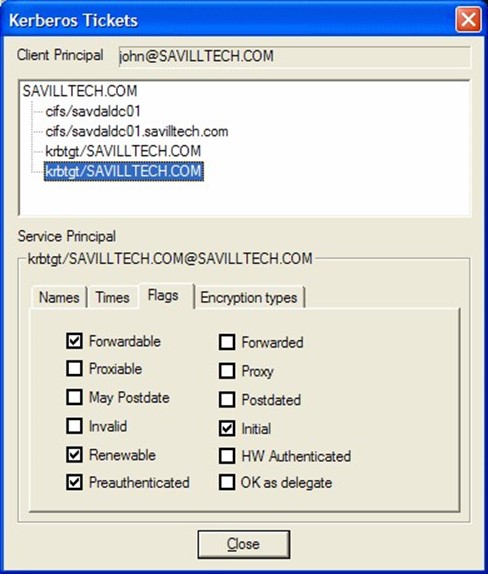
Figure 4.2: The KerbTray utility.
This utility also provides access to several key properties of a ticket, including whether it can be renewed, whether it can be forwarded by a server to another server in order to pass along a user's authentication, and so forth.
Kerberos' primary weakness is a dependence on time for the initial TGT‐requesting authenticator. In order to prevent someone from capturing an authenticator on the network and then replaying it at a later time, Kerberos requires authenticators to be timestamped, and will by default reject any authenticator more than a few minutes old. Domain computers synchronize their time with their authenticating domain controller (after authentication), and domain controllers synchronize with the domain's PDC Emulator roleholder. Without this time sync, computers' clocks would tend to drift, taking them outside the few‐minutes Kerberos "window" and making authentication impossible.
Authorization: DACLs
As I've already mentioned, AD's main role is authentication. However, for information— such as users and computers, along with configuration objects like sites and services— inside the directory, AD also performs its own authorization and auditing.
Every AD objects is secured with a discretionary access list. DACLs follow the same basic structure as Windows' NTFS file permissions. The DACL consists of a list of access control entries. Each ACE grants or denies specific permission to a single security principle, which would be a user or a group. Figure 4.3 shows a pretty typical AD permissions dialog.

Figure 4.3: AD permissions dialog.
As with NTFS permissions, objects can have directly‐applied ACEs in their DACLs, and they can inherit ACEs from containing objects' DACLs. In most directory implementations, for example, user objects have few or no directly‐defined ACEs but instead inherit all of their ACEs from a containing organizational unit (OU).
ACEs actually consist of a permissions mask (which defines the permissions the ACE is granting or denying) and a SID. When displaying ACEs in a dialog box, Windows translates those SIDs to user and group names. Doing so requires a quick lookup in the directory, so in a busy network, it's sometimes possible to see the SIDs for a brief moment before they're replaced with the looked‐up user or group names.
It's important to understand that, in AD, computers are the same kind of security principle as a user, meaning computers don't have any special permissions. For example, if a Routing and Remote Access Server (RRAS) machine is attempting to authenticate a dial‐in user, the server might need to look at properties of the user's AD account to see whether the user has any dial‐in time restrictions. Doing so requires that the server have permission to read certain attributes of the user's account, which is why the dialog in Figure 4.2 shows the "RAS and IAS Servers" user group as having permissions to the user's account—without that permission, the server would be unable to examine the user's account to determine whether the dial‐in was to be allowed.
Auditing: SACLs
Auditing is defined in Security Access Control Lists (SACLs), which simply define what actions, by which users, will result in a log entry being made in Windows' security log. We'll cover auditing in more detail in the next chapter.
Configuration
AD, like any Windows component, has its own configuration settings, many of which can affect security. For example, consider Figure 4.4, which shows the Group Policy Object (GPO) settings for Kerberos.
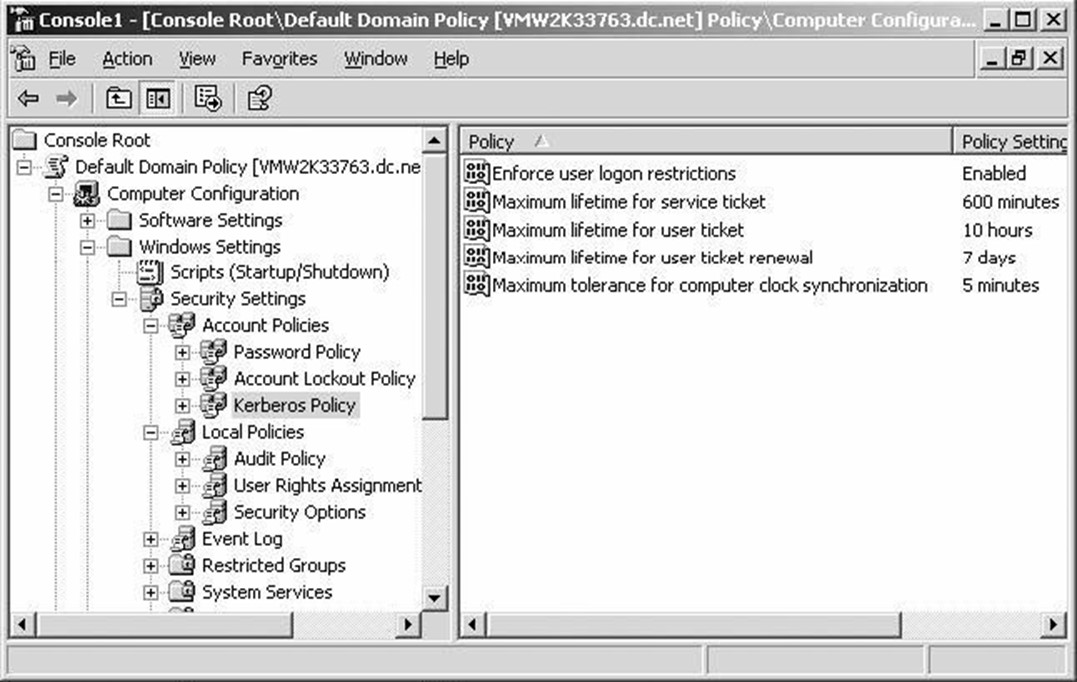
Figure 4.4: Kerberos settings in a GPO.
These settings definitely have a security impact: They control how long a Kerberos ticket is valid, how often it can be renewed, how much time slip is allowed for clock mis‐sync, and so forth.
Part of the challenge with AD is that settings like these are scattered all over the place. Some are in the registry and can be modified with a GPO; others live within AD itself, and are accessed by various consoles and command‐line tools. Keeping everything straight can be complex; in newer versions of Windows, Microsoft has added a Best Practices Analyzer (BPA), which helps review all of these settings and make recommendations about how to configure them for better security, reliability, performance, and so forth. Figure 4.5 shows an example.
Figure 4.5: A BPA report example.
The "Best Practices" used by this tool are developed by Microsoft, using their own experience with the product, as well as the experiences of major customers. The BPA is new for Windows Server 2008 R2, and the AD model covers a pretty large array of settings. Models are also available for DNS and Certificate Services.
Distributed vs. Centralized Permissions Management
AD plays such a central role in authentication that it's easy to forget that the directory really has no role whatsoever in enterprise‐wide authorization or auditing. In other words, the directory knows who you are, but it has no clue what you're allowed to do.
This is both a strength and a benefit. With Windows' current architecture, each server maintains its own DACLs on the resources it contains, which might consist of databases, files, mailboxes, or whatever. There's no need to build the robust "central permissions infrastructure" that would be required if servers didn't maintain their own DACLs. Thus, the architecture is better‐performing and lower‐cost.
Unfortunately, Windows' distribution permissions management evolved when the operating system (OS) was primarily used by small workgroups, not by massive companies with millions of securables. The disadvantage of the distributed permissions management is that certain security questions—such as, "What resources does this user have access to?" are impractical to the point of impossibility. The only way to answer the question would be to manually scan every single DACL on every single server to see where that user—or a group he or she was a member of—appears. Doing that on‐demand just isn't feasible. And think about it: When a new user starts with a company, someone needs to know what permissions he or she needs. The answer is usually, "Oh, give him the same permissions as so‐and‐so, who does the same job." The problem is that there's no way to find out what permissions so‐and‐so has in the first place!
AD's user groups do allow for some degree of centralization if an organization's administrators are careful. In other words, if you assign permissions only to user groups (which is a practice Microsoft recommends), then you can centrally manage those groups' membership within AD. However, although this practice makes it easier to give a new user the "same permissions as that other guy," it's still impractical to get an inventory of what resources a given group has access to because you still have to scan all of the DACLs. There's also no way of enforcing this practice, and many administrators have "put out a fire" by ignoring their organization's groups‐only policy and applying an ACE for a single user to a DACL. Over time, these "one‐off quick fixes" add up to an impossible‐to‐manage permissions system.
In fact, most Windows‐based networks that aren't using some kind of third‐party permissions management utility are, in all likelihood, managed very poorly from a permissions perspective. They try to do a good job as much as possible, but the way the distributed system works is simply stacked against them.
There are (as I'll discuss later in this chapter) third‐party utilities that can provide that kind of inventory—but they do so by scanning every single DACL. They usually do so over several days initially, building a searchable database of permissions. Agents installed on servers can then watch for permissions changes and report those "deltas" to the database, keeping it up to date.
Do‐It‐Yourself Security Reporting and Changes
Security is one of those things that you're almost constantly looking at for one reason or another. I've already mentioned the BPA, which is a good way to get a basic look at your AD infrastructure's security, performance, and other configuration settings. Without spending any money on third‐party tools, you can definitely do some decent reporting.
Permissions
Reporting on permissions is, frankly, hard, due entirely to the way they're stored in Windows. If you want to build your own permissions‐reporting tool, you're going to have to scan through a lot of servers. Even answering the question, "What resources can Jill access on this single server?" can be time‐consuming because you have to scan through every DACL on the server. Even if most files and folders inherit security from a top‐level folder, you can't assume that to be the case—you're going to have to check every file and folder to make sure.
For that reason, I think building your own permissions‐reporting tools is simply impractical. Whatever tools you may have at your disposal—VBScript, Windows PowerShell, and so forth—are going to be too slow to accomplish the task in any reasonable amount of time. Sorry—it's not you, it's Windows.
Directory Objects
Reporting on directory objects—disabled users, old user accounts, locked‐out users, and so forth—is easier to do yourself. The AD Users and Computers (ADUC) console provides a Custom Query option that makes this pretty straightforward. As Figure 4.6 shows, you can very easily create a query that shows all users that haven't logged on in, say, the last 90 days—a good starting point for a "stale accounts" report.

Figure 4.6 Building a custom AD query.
Windows PowerShell can also be used to generate custom reports of a sort. For example, Figure 4.7 shows a PowerShell command that's generating a list of user accounts that have never had their password set. Again, this is a good starting point for other security activities, such as possibly disabling or deleting those accounts.
Figure 4.7: Custom reports in PowerShell.
Should You Rethink Your Security Design?
Given the extreme complexity of dealing with permissions on your own, while following best practices, you might want to consider a redesign of your permissions. How you proceed depends a bit upon your goals.
For example, many companies are now moving—or trying to move—to rolebased security. The idea is that you create a top‐level set of roles, which correspond directly to job titles or job responsibilities within your organization. You drop people into those roles, and they pick up the necessary permissions.
In a very small, single‐domain environment that has good discipline, you can accomplish this with AD's domain user groups. In larger, multi‐domain environments, that becomes a lot harder. Groups are often still used as an under‐the‐hood means of implementing roles' permissions, but a role will usually be represented by multiple groups because roles span the entire organization, not just a single domain or forest. It's generally considered impossible or at least impractical to implement true role‐based permissions in a complex AD environment using only AD's native tools; you generally have to go with a third‐party role‐based management system that overlays the native AD and Windows security.
Regardless, most companies tend to get really jittery when it comes to redesigning their permissions architecture, mainly because doing so without some kind of third‐party tool— which can be expensive—is a daunting task. You have to inventory everything, and figure out what resources someone might need access to. It's tough. Third‐party tools help because they can automate the process at a top‐level, taking much of the drudgework and guesswork out of it.
Third‐Party Security Capabilities
It's a rare organization that doesn't have some kind of third‐party AD tools to supplement its security management. The most common ones fall into the categories of reporting, permissions management, and auditing; we'll save auditing for the next chapter and just briefly focus on the first two.
Reporting
Third‐party reporting tools are very common, and can provide a lot of value. Figure 4.8 illustrates one tool, Enterprise Security Reporter, which is designed to report on a number of security‐related concerns within AD.
Figure 4.8 A look at the Enterprise Security Reporter.
Figure 4.9 shows another tool, Active Directory Reporter. This tool's focus is broader than security, but it does include a number of security‐related reports, as you can see.
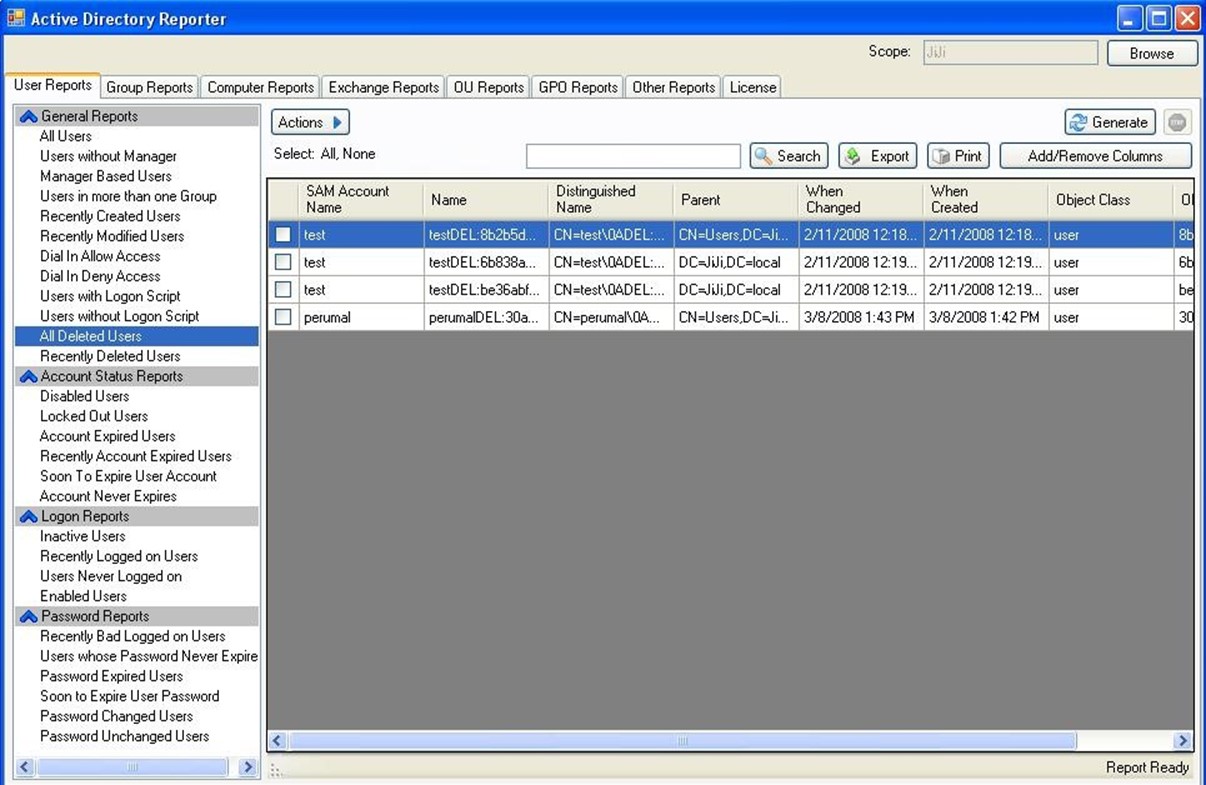
Figure 4.9: The Active Directory Reporter tool.
The idea here is that, rather than spending time (which is money) building your own reporting tools, the right third‐party reporting package can give you better‐looking and more robust reporting capabilities, making it easier to keep a handle on AD security.
Permissions Management
Third‐party permissions management tools typically seek to implement automated rolebased permissions for not only AD but also Windows file servers as well as other connected systems like Exchange, SQL Server, SharePoint, and so on. These systems provide a layer on top of the native permissions. They usually start by inventorying existing permissions into a central database. As you make changes to the database's permissions, those changes are pushed out to the relevant resources' native DACLs. Figure 4.10 shows one such tool, called ActiveRoles Server.
Figure 4.10: An example ActiveRoles Server window.
The idea with most of these tools is that you stop managing DACLs directly on resources. Instead, you manage them in the product, enabling it to offer role‐based permissions. The product then automates the application of those permissions to the actual resources, giving you centralized control and reporting—making it possible to quickly answer questions like, "What resources does Bill have access to?"
DNS Security
The last thing I'll offer in this chapter is an overview of DNS Security, more commonly called Domain Name System Security Extensions or simply DNSSEC. DNS obviously plays a vital role in AD's operation, and securing DNS is crucial to maintaining AD's own security and reliability.
The original DNS protocol didn't include any security. Microsoft's implementation of DNS, particularly with the recommended AD‐integrated DNS zones, applies a good deal of security by default. Dynamic DNS records are "owned" by their creators and can only be modified by them; other records can have security applied as well. The overall goal of DNSSEC is to prevent forged data from being inserted into the DNS zone database. If someone could do so, they could spoof internal servers and potentially gather sensitive information from unsuspecting users. Although the mutual authentication provided by the Kerberos protocol can help curtail that within a domain environment, Kerberos can't protect non‐domain computers, and those could still be spoofed via DNS.
Essentially, DNSSEC works by digitally signing DNS records using digital certificates. Several DNS record types specifically support this activity, including RRSIG, DNSKEY, DS, NSEC, NSEC3, and NSEC3PARAM. When clients make a DNS query, the DNS reply includes not only the traditional A (or AAAA) records, but also RRSIG records that contain a digital signature. The client can then use the DNS server's public key (obtainable in a DNSKEY record) to verify the signature, therefore validating the A or AAAA records.
Relatively few organizations today use DNSSEC, but Windows does support it, and has to a degree since Windows Server 2003. Full support is in Windows Server 2008 R2 and Windows 7. Keep in mind that DNS clients must be DNSSEC‐aware in order for the security features to be useful. Non‐aware clients can still use a DNSSEC‐enabled DNS server, but they will not be able to validate signatures and records.
Why don't more organizations use DNSSEC? Presently, it's not always well‐suited in a dynamic DNS environment. For example, creating a signed DNS zone requires you to export an active zone, sign it using a command‐line utility (which adds the DNSSEC records to the zone), then load the newly‐signed zone as the active database in your DNS server. Dynamic updates are disabled, essentially taking away a key feature that AD relies upon. For that reason, DNSSEC is most often used in external DNS zones, which tend to remain fairly static. That's actually not a bad thing: In a domain environment, DNS is secured by AD and spoofing of domain members is essentially made impossible by Kerberos. In a non‐domain environment, where you don't need dynamic DNS, DNSSEC is more practical and meets a need.
Be aware that DNSSEC support is still evolving: The world's DNS root zone doesn't yet support it, nor does the popular .COM top‐level domain. Without that support, it's possible to spoof entries in those top‐level zones. That support is coming, though. Interim security solutions are available in the meantime, and you can read about them at http://www.windowsitpro.com/article/dns2/DNS‐Enhancements‐in‐Windows‐Server2008‐R2/2.aspx
Active Directory Auditing
The previous chapter was about Active Directory's (AD's) declarative security—that is, how you tell the directory who has permission to do what. We also had a look at how AD's security is designed and built, and how AD as an authentication mechanism interfaces with Windows' native authorization mechanisms. Those were the first two of the "three As," and the third one—auditing or accounting—is the focus of this chapter.
Goals of Native Auditing
Auditing has a fairly simply goal: Keep track of everything everyone is doing. Within the context of AD, that means keeping track of all uses of privilege, such as changing group memberships or unlocking user accounts. It also means keeping track of account activity, such as successful logons and failed logons. Extending that scope to Windows, auditing includes keeping track of file and folder access as well as changes to file permissions.
Your goals for auditing might differ somewhat from the goals of the operating system's (OS's) auditing architecture. Keep in mind that the auditing system used in Windows— including AD, which essentially just copied the architecture of the file system—dates back to the early 1990s when Windows NT was being designed and written. At that time, Microsoft couldn't have predicted organizations with thousands of file servers, dozens or hundreds of domain controllers, and thousands of other servers running Exchange, SQL Server, SharePoint, and other business platforms. The fact is that Windows' native auditing architecture doesn't always scale well to especially large environments, or even to some midsize ones—a fact we'll explore later in this chapter. So although you might want to audit every single event in your environment, actually doing so may create performance challenges, management challenges, and even logistical challenges. For right now, let's just assume your goal is indeed to audit everything that happens in your environment, and see where the architecture takes us.
Native Auditing Architecture
In the previous chapter, you learned that permissions are applied to a Discretionary Access Control List (DACL). Each DACL consists of one or more Access Control Entries (ACEs), and each ACE grants or denies a specific set of permissions to a single security principal—that is, a user or a group. The DACL is the authorization part of the AAA model: AD authenticates you, and gives you a security token containing a unique Security Identifier (SID). That SID is compared with the ACEs in a DACL to determine your permissions on a given resources. Auditing works in much the same way. A Security Auditing Control List (SACL) consists of one or more entries. Each entry designates a specific auditing action for activities conducted by a single user or group. The SACL is attached to a resource, like a file or directory object, and whenever the specified security principal engages in the specified activity with that resource, the action is logged. Typically, you have the ability to log "success" and/or "failure" actions. That is, you can choose to log an entry when someone successfully exercises their permissions or when they attempt to do so and are denied.
Figure 5.1 shows a SACL configuration for AD. As you can see, this resource—the "Domain Controllers" organizational unit (OU)—is configured to log several success actions performed by the special Everyone group. That is, whenever anyone successful performs any of these actions, an audit entry will be generated.

Figure 5.1: SACL in AD.
Exactly what actions you can audit depends on what resource you're working with. For example, Figure 5.2 shows a file system SACL, and you can see that very different actions are available.
Figure 5.2: A file system SACL.
Here, you can choose to audit things like creating folders, reading attributes, deleting files, and so on. Each resource, then, can have its own SACL. In practice, most of us assign SACLs at a fairly high level in the hierarchy and let those settings propagate to lower‐level objects through inheritance. That way, we only have to manage SACLs in a relatively small number of places. But we still have to configure at least one top‐level SACL per server, per major system. That is, each server will need a top‐level SACL on at least the root of each logical drive, we'll need a separate SACL on the root of AD, and so on.
Other products may or may not follow this pattern. Exchange Server, for example, uses a similar structure for its auditing; SQL Server does not, nor does SharePoint. We'll stick with AD and the core Windows OS for the discussion in this chapter.
Once an auditable action occurs, Windows generates an audit entry. These are stored in the Security event log, which Figure 5.3 shows. A problem with this log is that every auditing event goes into it. Although it's nice to have everything in one big, central pile, it can make it tough to pull out specific entries. Again, this reflects Microsoft's relatively limited original vision for the auditing system.

Figure 5.3: The Security event log.
Each Windows server maintains its own individual Security event log—that includes domain controllers. Although AD's SACLs can be configured on any domain controller, and will replicate to all of them, only the domain controller that actually handles a given action will create an audit entry for it. The result is a centrally‐configured auditing policy but a highly‐distributed auditing log.
Figure 5.4 shows what these audit entries look like. They're fairly technical, and often include raw SIDs and other under‐the‐hood information. This example shows a successful domain logon, processed using the native Kerberos protocol. The user name and domain have been blanked out for this example but would normally be populated when a real user logs on.
Figure 5.4: An example audit entry.
Microsoft has already begun to address the issue of one log holding so much information. In Windows Vista and Windows Server 2008, Microsoft introduced a parallel event log architecture that makes it easier for each product or technology to maintain its own log. This was always possible—the original Application, System, and Security logs have long been supplemented by logs for Directory Services, for example. But this new architecture is more robust in several ways. Figure 5.5 shows some of the old and new‐style logs.

Figure 5.5: New logs alongside the old logs.
Unlike DACLs, SACLs are not immediately utilized by the OS. SACLs simply designate what actions, what security principals, should be audited; the auditing system itself must also be turned on in order for events to be written to the logs. Figure 5.6 shows where that is usually configured in a Group Policy object (GPO).
Most organizations will configure auditing at a high‐level GPO, such as one applied to all domain controllers, or even to all servers in the domain. The GPO pictured is specifically setting the audit policy, which includes turning on auditing of logon events, account management activity, access to AD, and so forth. The audit policy, as well as resource SACLs, must both be configured in order to generate the desired auditing events.

Figure 5.6: Configuring auditing in a GPO.
This is where you have to use some caution. You don't want to turn on full‐bore auditing without thinking about the consequences. A domain controller can generate thousands of logon events every minute during the busy morning logging‐on rush, and generating all of those events requires computing power. If auditing all of those events is truly a requirement, then you're going to have to size your domain controllers accordingly to handle the load. The same goes for file servers: If a file server is expected to generate an event for every successful or failed file access attempt, it's going to need to have the computing power necessary to pull it off.
Generating that much log activity can also pound the actual event logs pretty hard. As Figure 5.7 shows, you'll want to pair your audit policy with a well‐planned event log policy, setting event logs' sizes, rollover behavior, and other settings to accommodate the workload you plan for them to handle.
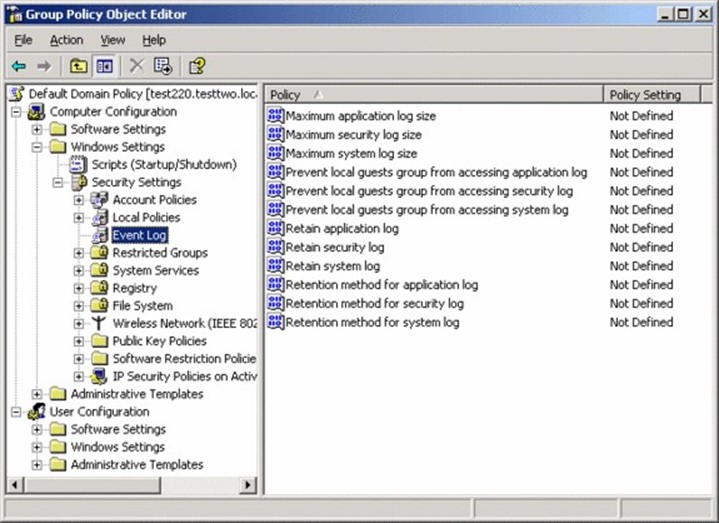
Figure 5.7: Configuring event log settings in a GPO.
The Security log—which is where auditing events are written—can be especially tricky. With the Application log, you might feel comfortable simply allowing it to overwrite itself when it gets full. For the Security log, you can't practically do that, or you'd open up the door for auditing information to be lost. Instead, you'll have to configure an appropriate log size, and implement maintenance procedures to archive and clear the log on a regular basis—perhaps as often as every evening, depending upon the load you're putting on that log.
A common criticism of Windows' native event logs is their highly‐distributed nature. For example, an administrator could modify a group membership on one domain controller, connect to a second domain controller to use an account in that group, and connect to a third domain controller to reset the group membership. All three actions would be logged in three different Security event logs, making it difficult to correlate those independent events into a chain of activity.
Microsoft's initial solution to this problem, introduced in Windows Server 2008, is event log forwarding. Pictured in Figure 5.8, the idea is that individual servers can forward events to a central server, which collects all of the events in its own log.
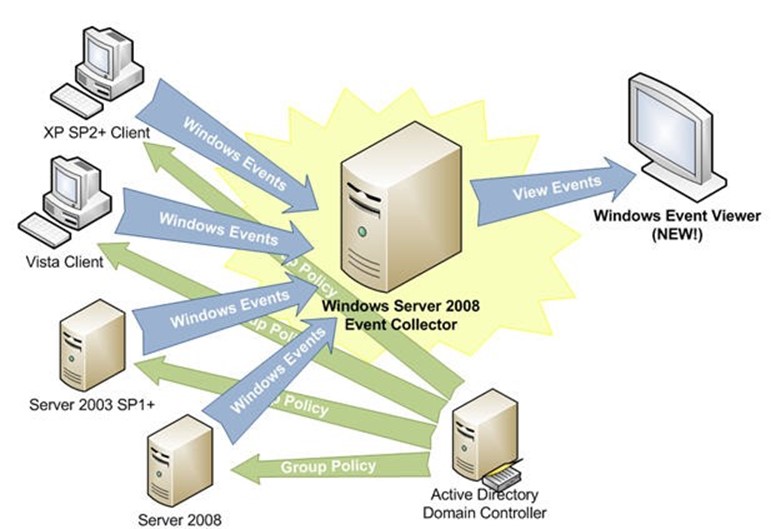
Figure 5.8: Event log forwarding.
As indicated, this feature can be configured with Group Policy, making it centrally controllable. The approach still has some significant drawbacks, however, which we'll discuss later in this chapter.
So that's how the native auditing system is built. Let's talk a bit more about how organizations want to use that system, and see where it might need enhancement.
Common Business Goals for Auditing
Unlike the 1990s when Windows NT was designed, most businesses today are subject to some kind of security policy. In many cases, that policy incorporates external requirements from industry rules or even legislation. Those requirements may include a need to audit every successful and failed action for pretty much everything in the environment—and that generates a lot of auditing traffic.
Another goal is for that auditing information to be tamperproof, or at least tamper‐evident. In other words, the people being audited—including administrators—shouldn't be able to remove their own audit activity from the audit log. Organizations also want to be able to search, filter, and report on those events. For example, an auditor might want to see every audit entry that corresponds to a reconfiguration of AD's audit policy, then match each of those events to an approved action. That lets an auditor see that the only changes made to the directory were those that had been formally documented and approved.
Organizations also need to use these audit events for troubleshooting purposes. When something goes wrong in the environment, answering the question "What changed?" is usually the quickest way to solve the problem—and the audit logs should be able to answer that question quickly and effectively. So how does the native auditing system hold up?
Weaknesses of Native Auditing
Unfortunately, the native auditing system does not always hold up well. I really don't regard this as a weakness on Microsoft's part—after all, their job isn't to anticipate every possible business need, but rather provide a platform on which other software can be deployed to meet specific, varying business needs. They've done that. The native auditing architecture is bare‐bones, suitable for the smallest organizations that are less likely to be able to afford add‐on software to meet specific business needs. The native system is also close to three decades old, and you can't always expect systems of that age to meet every possible modern requirement.
Goal one, being able to audit everything, is certainly possible within Windows—although you'll need to play log capacity and server performance around that goal. The native event log architecture isn't as performance‐transparent as it perhaps could be, and asking a server to audit tens of thousands of events an hour will create an impact on that server.
Goal two—a tamper‐evident log—is where the system really falls apart. Unfortunately, it's just not feasible to take away administrators' ability to clear the event log. You can do it, by carefully tweaking privileges, creating dedicated log‐management user accounts, and so on—but it's complex, and many organizations find it impractical.
Even assuming you do so, meeting the next goal—centralized reporting, filtering, and alerting—isn't practical, either. Event log forwarding, even when used, doesn't occur in real time—there can be significant delays in events being forwarded. Even when you do rely on event forwarding, you're massing a log of log information into a single place, and relying on an extremely primitive event viewer for querying that log. Figure 5.9 shows the filtering capabilities of the native tool, and they're indeed primitive.
Figure 5.9: Native event log filtering.
As shown, you can filter for specific event types, and filter for specific text in the event description, as well as other criteria. But there's no way to correlate multiple related events in a chain of activity, and there's no reporting mechanism to speak of.
As for the final goal of using these events for troubleshooting—well, good luck. It's certainly possible, although it usually takes the form of, "see what's in the log, look up the event IDs to see what they mean, and figure out if that's relevant to the current problem." It's much harder to ask the native event viewer to give you, "all changes made to AD within the past 4 hours." Although there will be events related to those changes—provided your audit policy is capturing them—the event log isn't really designed to facilitate change management or change auditing. It isn't auditing the change, per se, it's auditing the fact that someone made a change.
As Figure 5.10 shows, Windows Server 2008 AD did start capturing "before and after" values in changes, making it a bit more usable for change auditing. However, the feature still isn't pervasive throughout all of AD, and finding the actual events in a massive log file can still be challenging.
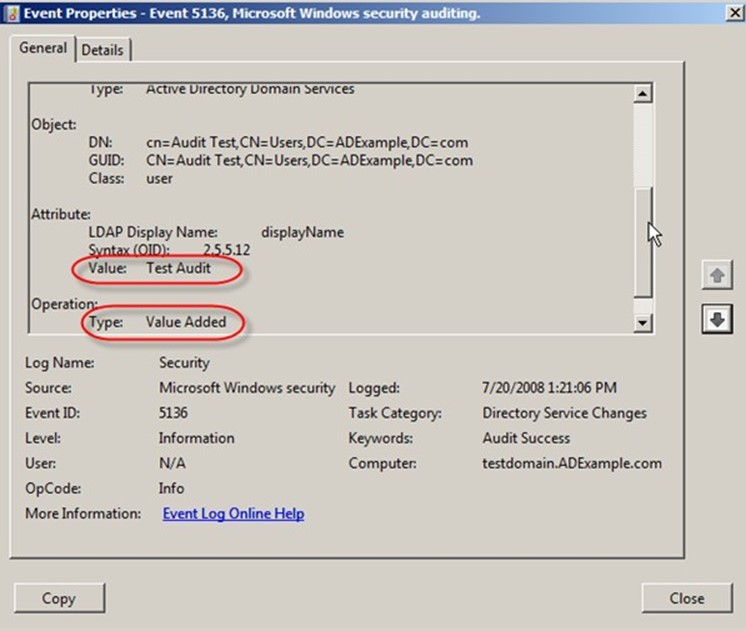
Figure 5.10: Enhanced events in Windows Server 2008.
In most environments, a successful auditing program almost always involves third‐party auditing supplements.
Third‐Party Auditing Capabilities
Third‐party auditing tools take several approaches to supplementing Windows' native capabilities. First, these tools may do a better (and faster) job of collecting events from multiple servers' logs into a central location. Often, that central location is a SQL Server database, although other tools will always forward events in real‐time to an external logging mechanism, such as a syslog server—as Figure 5.11 illustrates.
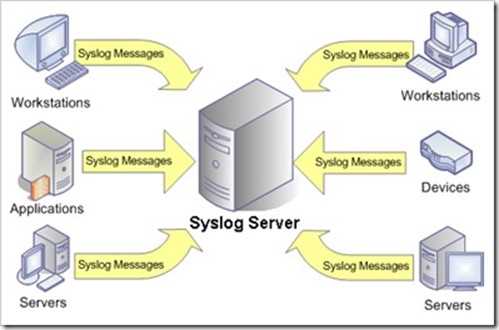
Figure 5.11: Forwarding events to a syslog server.
The idea is mainly to get the events out of Windows as quickly as possible, and into some separate system that can be secured differently from the environment's event logs. Databases are popular choices because they can be secured and they naturally lend themselves to complex queries, and thus, to reporting capabilities. In fact, many third‐party auditing tools collect events in SQL Server mainly to leverage SQL Server Reporting Services as a reporting mechanism.
Third‐party tools may also tap directly into native Application Programming Interfaces (APIs) to collect audit information—in addition to, or instead of, using the native event logs. These APIs often offer more detailed information, including better "before and after" details. In some cases, using the APIs may offer a better‐performing way of collecting the information, reducing server load.
Once the event data is centrally located, third‐party tools can kick in with real‐time alerts, reporting, event archiving, analysis and collation, and much more. The trick is in getting the events into a single spot that can be queried quickly and effectively.
Active Directory Best Practices
This chapter is a kind of "miscellaneous best practices" list. The trick with AD and best practices is that there's never any one right answer for every organization. You have to temper everything with what's right for your organization. So really, this chapter is intended to simply give you things to think about within your environment, and ideas that stem from what's worked well for other folks in situations that might be similar to your own.
Should You Rethink Your Forest and Domain Design?
First of all, step back and take a look at your domain and forest design. How perfect is it? AD design unfortunately has two conflicting goals: One is to support your Group Policy deployment, and the other is to support delegation of permissions. For the first goal, you might organize AD to really facilitate using a minimal number of effective Group Policy Objects (GPOs), especially if you need differing GPO settings for various company departments and divisions. The second goal focuses on who will manage AD objects: If you plan to delegate permissions to reset passwords, for example, then organizing your directory to group those delegated user objects will make the actual delegation easier to set up and maintain.
Keep in mind that Group Policy is the one thing you pretty much can't separate from the directory. From a security and delegation perspective, third‐party tools can abstract your directory design. For example, many third‐party identity and access management (IAM) tools enable you to delegate permission over objects that are distributed throughout the directory. You essentially use the tool to manage the delegation, and it deals with whatever ugly, under‐the‐hood permissions it needs to. In some cases, these tools don't actually modify the underlying directory permissions at all. Instead, they provide "in‐tool" delegation, meaning they act as a kind of proxy manager, providing different user interfaces for delegated users to accomplish tasks like resetting passwords or modifying user accounts. That kind of abstraction can let your underlying directory structure conform to other needs—like those of you Group Policy deployment.
Restructuring a domain or forest can be just as complex, risky, and frustrating as migrating to AD was in the first place. The main reason to consider this kind of project is if your directory has grown, and been extended, organically over time. Corporate merges and acquisitions are a common root cause of that kind of growth. You may also find that whoever originally designed the directory didn't have a good understanding of how to do so, or that the company's needs and operations have changed since the original design was put in place. In any event, rethinking the design can have a significant positive impact on operations, maintenance, disaster recovery, and even on performance and usability—so it's worth at least considering the project. Determine whether the business benefits would outweigh the potential risks, and consider ways to mitigate those risks. For example, many third parties produce migration/restructuring tools that can largely automate much of the process, provide zero‐impact testing capabilities, and even roll back migration changes if they prove to be problematic. Those tools obviously have a cost, so you'll have to weigh that cost against the business benefits and see if it looks like a win.
AD Disaster Recovery
Disaster recovery and business continuity is always a concern, so let's look at general best practices for making sure that your directory can be recovered in the event of a failure. We're not going to look at the more commonly‐needed single‐object recovery just yet— there's a section in this chapter for that coming up.
Single Domain Controller
Probably the most common failure scenario in AD is the failure of a single domain controller, often due to a hardware failure. What do you do when this happens? Well, if you've built your domain controllers properly, you won't need to do much. My assumption is that your domain controllers are doing very little apart from being domain controllers. They may be running DNS, and if they are it should be an AD‐integrated DNS zone. If you don't use Microsoft's DNS, don't put your DNS servers on your domain controllers. That way, if a domain controller fails, you just rebuild it.
Keep in mind that, in AD, no domain controller is unique. They're all the same. If one fails, it's no big deal—the others just keep moving right along. Build a replacement machine (something that's trivial if you're using virtual machines), promote it to be a domain controller, and sit back and let replication take over. In other words, you don't bother backing up every single domain controller because they each act as backups for each other.
The only time this might not be a straightforward approach is when the failed domain controller is on the other side of a slow WAN link from any other domain controllers.
Waiting for a large domain to replicate across the WAN can be time consuming. If you don't mind waiting, it's still the best way to go. About the only other option is to keep a backup of those remote domain controllers—making sure it's never more than a few days old. That way you can restore from that backup, and let a much lesser amount of replication bring the domain controller back up to date. Tape backups are fine for this approach, and they're easy for people with minimal IT skills to operate, so in cases where you don't have a lot of local expertise helping you out, it's not a bad approach.
You'll often see smaller remote offices using an "all in one" server—a single machine acting as domain controller, DNS, DHCP, file server, print server, fax server, and who knows what else. Try to avoid that: In this day and age, that physical machine should be a virtualization host, with some of those roles split up between different machines. Either way, tape‐based backup can start to become complex and large, and I recommend moving to a real‐time, disk‐based backup. That'll get the server back online quicker in the event of a failure, and it'll do a better job of capturing all the data that the server houses.
Entire Domain
It's pretty rare to lose an entire domain. As it's almost impossible to lose every single domain controller at the same time, "losing" the domain usually means some vast and tragic administrator error. The only resolution is, of course, to have a good—and recent— backup.
Again, this is where I firmly reject tape‐based backup and recommend real‐time disk‐based backups instead (read my book, The Definitive Guide to Windows Application and Server Backup 2.0, from Realtime Publishers, for an exhaustive treatment of the subject). A realtime disk‐based backup can get a domain controller up and running in minutes or hours, not days, and you'll lose no more than a few minutes' worth of activity from the domain.
Disk‐based backups can also (usually, depending on the vendor) be replicated off‐site, making them suitable for true disaster recovery where you've lost an entire data center, or lost the use of it, due to some disaster such as flood, fire, meteor strikes, and the like.
Entire Forest
It is vanishingly rare to lose an entire AD forest. I was once told that there are something like less than a dozen documented, real‐world (that is, non‐lab‐based) occurrences. Still, the threat of whole‐forest‐loss is enough that Microsoft officially supports forest recovery, and a handful of third‐party vendors make whole‐forest recovery products.
If you feel that losing your entire AD forest is a threat you must be prepared to face, take my advice and buy a forest recovery product now (they're no good once the forest has actually failed; they have to grab the necessary backups first). Recovering a forest is no trivial task, and having a tool on‐hand will get you back up and running more quickly than the alternative, which is usually contacting Microsoft product support for assistance.
AD Restores and Recycle Bins
Let's turn briefly to the subject of single‐object recovery within AD. Prior to Windows Server 2008 R2, Microsoft didn't have a good, supported solution for AD single‐object recovery. Their approach was to take a domain controller offline, put it in Directory Services Recovery Mode, perform an authoritative restore of whatever directory object(s) you lost, then bring the domain controller back online and let it replicate its changes.
Let's be clear on what I mean by singleobject recovery, too: Bringing an entire deleted object back, including all of its attributes. You cannot do this by simply un‐tombstoning a deleted object because when AD deletes and tombstones an object, it removes the object's attributes.
In Windows Server 2008 R2, Microsoft introduced a feature called the "Active Directory Recycle Bin," a name of which I am not a fan. This feature is only available when the entire forest is running at the Win2008R2 functional level (meaning every domain must also be running at this level), and the feature must be specifically turned on—a one‐time action that can't be undone. Figure 6.1 shows the PowerShell command needed to enable the feature.

Figure 6.1: Enabling the "Recycle Bin" feature.
When on, deleted objects are copied—attributes intact—into a "Recycle Bin" container within the directory. Only you won't actually see a Recycle Bin icon, and you can't drag objects out of the "bin" back into the main directory (that lack of actual "Recycle Bin" functionality is why I wish they hadn't called it that). As Figure 6.2 shows, you can use GUI tools to view the new "Deleted Objects" container and its contents.
Figure 6.2: Viewing the Deleted Objects container.
To actually restore an object requires the use of rather byzantine Windows PowerShell commands; there's no actual GUI component for working with "recycled" AD objects.
The "Recycle Bin" feature is also a bit unintuitive. For example, if you need to restore an OU and its contents, it's a two‐step process: Restore the OU, then the objects that used to live in it. Some organizations will have concerns about that recycled information—including employees' personally‐identifiable information (PII)—persisting in the directory past the objects' deletion. Although a traditional backup would also persist that information, it doesn't do so "live" in the directory, and that makes a difference to some folks.
The "Recycle Bin" feature is also limited to object restoration; it can't restore a single attribute from an object that may have been improperly changed.
So this new "Recycle Bin" feature is, at best, a bare‐bones way of getting single‐object recovery for a very small organization that will not consider third‐party tools. Me, I'm a fan of third‐party tools. A single AD disaster recovery solution can give you a true, graphical recycle bin with drag‐and‐drop recovery and single‐attribute recovery and will scale all the way up to complete domain or forest recovery if necessary. Everything but a domain/forest restore can be done without taking a domain controller offline, helping everything stay productive, and in most cases, these tools integrate into the familiar Active Directory Users and Computers console, making them even easier and more accessible.
You could argue that Microsoft should build that kind of functionality into the base product. Maybe so, maybe no: Every third‐party recovery tool I've looked at works slightly differently, and those differences reflect different customer needs. Microsoft would only be able to squeeze us all into the same functionality; as the situation stands, we can select from whatever solution fits our particular needs the best. Microsoft, as I've suggested in earlier chapters, needs to deliver a good platform—I don't necessarily think they should deliver every possible permutation of a management tool that an organization might need.
This Isn't Retail
I've made this argument about third‐party tools before. Too often, I see a "packaged retail" mentality around computer software. You go and buy Microsoft Office, you don't expect to have to buy add‐ons to make it work. Okay, I get that—Office is an end‐user product. Most end‐user products come complete: Cars come complete. Even kids' games sometimes ship with batteries included.
Windows, as a server operating system (OS), isn't a packaged retail end‐user product. It's more like a house: The builder is giving you a platform, and you expect to spend money above and beyond that structure. The structure should come with good plumbing, but you attach your own faucets. The floors should be flat and solid, but you're putting your own furniture on them.
Yes, some builders will throw in minimal versions of these add‐ons—kitchen appliances, bathroom fixtures, and so forth. But these are almost always the bare‐minimum versions. They're rarely the high‐end, custom stuff you know you want.
Sure, you can buy a house that comes with all the custom high‐end stuff, but that's like working with a Microsoft VAR. In addition to the home builder (Microsoft), you've also got a designer (the VAR) buying your curtains, furniture, and so forth, and giving you the resulting product for a single package price. You can do that with Windows: Get the base platform and all the third‐party tools needed to make it awesome, all from one vendor, and all for one price. That vendor just isn't Microsoft, because they're in the business of making the basic structure, not customizing it to fit every possible business need.
When it comes to Windows as a server OS, you have to include certain thirdparty tools as part of the cost of doing business. The cost for the Windows license is just the beginning: If you have auditing needs, or disaster recovery needs, those are going to cost extra. If you're in the type of company that doesn't like to spend money on "extras" anytime, ever, then you shouldn't expect to be able to meet all of the business' needs all of the time, either.
Security
I don't actually have a lot to say on the topic of security best practices. I think Microsoft's Best Practices Analyzer (BPA—which will be discussed in the final section of this chapter) does a good job of covering the high‐level security settings in AD; anything else really comes down to your specific business and operational needs. Do you delegate permissions within the directory or rely on a more monolithic permissions structure where Domain Admins do all of the work? Neither approach is wrong; it simply depends on how your organization is structured for that kind of administration.
Replication Topology
Definitely take the time, now and then, to review your AD replication topology. Using your site architecture, draw out a picture of the replication topology, like the one in Figure 6.3.
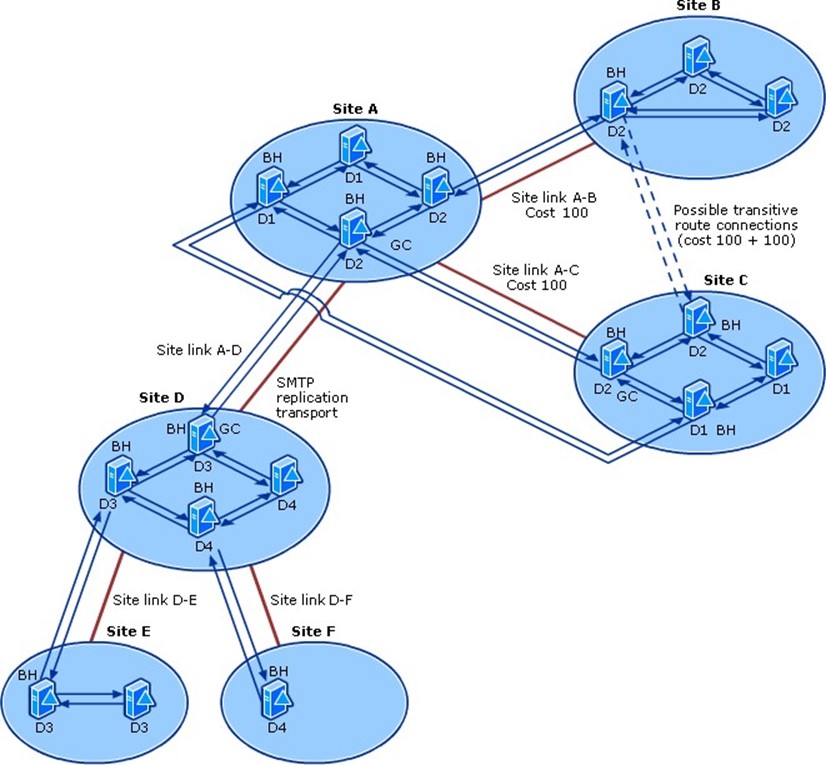
Figure 6.3: Mapping your replication topology.
What's even better are some of the third‐party (including some free ones out there) tools that can analyze your directory and draw this type of picture for you—as Figure 6.4 shows. The differences between your actual topology, and the one you think you have, can be enlightening.
Figure 6.4: Toolgenerated actual replication topology.
The goal should be to simply ensure that no domain controller is too many steps away from every other domain controller so that replication can quickly get changes out to every domain controller in a minimum number of "hops." At the same time, you want to ensure that the physical WAN links can handle the replication traffic you're putting on them. That's especially true when you have a lot of manually‐configured site link bridges, which deliberately "double up" the traffic on your WAN links in an effort to reduce replication hops between distant sites.
It's really important not to rely solely on a hand‐drawn diagram of your replication topology because AD won't always make the exact same calculations as you about which domain controllers should be bridgeheads, and it's easy to overlook things like site link costs that might be making AD calculate unexpected and unwanted topologies. Get your hands on some kind of tool that can draw a topology based on what AD is actually doing, and compare that with your hand‐drawn "expectation diagram."
FSMO Placement
Recommendations on FSMO placement have changed over the years; http://support.microsoft.com/kb/223346 offers the latest guidance. In general, it's considered safe to stack all of the FSMO roles onto a single domain controller, provided it is located at a hub site (that is, has good physical WAN or LAN connectivity to most other sites). The only exception is for environments that don't have a Global Catalog (GC) hosted on every domain controller; in those cases, move the infrastructure master to a domain controller that doesn't host the GC.
Some FSMO roles are forest‐wide: The schema master and domain naming master should co‐locate with the PDC emulator of the forest root domain. Again, that domain controller should be well‐connected to the other domain controllers in the forest, ideally located at a hub site that has good WAN connectivity to most other sites.
Virtualization
Can you virtualize your AD infrastructure? Of course you can. Should you? In a word, yes. You should. The long‐term benefits of virtualization have been proved by scientists: easier workload management, easier disaster recovery, easier scalability, lower power requirements, lower cooling requirements, less data center space—and the list goes on and on.
Frankly, there's no reason not to. AD works and plays quite well in a virtual environment. In fact, with modern memory overcommit, you can really leverage AD's unique usage patterns. AD gets busy and needs a lot of memory in the mornings when everyone is logging on. So co‐locate your AD virtual machines with virtual machines that run other tasks, such as line‐of‐business applications. As logon traffic settles, people grab the bagel, and get to work, AD virtual machines will need less physical memory, and that can then be devoted to the line‐of‐business virtual machines. Just scatter your AD virtual machines across several virtualization hosts and you're golden.
And consider installing AD on Server Core, not the full install of Windows. Server Core has a vastly smaller footprint, meaning more of the virtual machine's resources can go to AD. Server Core requires less maintenance (it has a lot fewer patches over time than the full install), so you'll spend less time maintaining your virtual machines. Server Core's disk footprint is smaller, making it easier to move from host to host. And Server Core can still run all of your management tools, agents, anti‐malware, and other stuff (popular myths to the contrary). If you're accustomed to running DNS, DHCP, WINS, and other infrastructure functions on your domain controllers—well, Server Core runs those too. And those roles are completely manageable via the same GUI consoles you use today: Active Directory Users and Computers, DNS Management, and so on. You'll find yourself logging onto the console very rarely, if at all (even Server Manager supports remote connectivity in Win2008R2).
Ongoing Maintenance
Aside from object‐level maintenance—you know, cleaning up disabled users, stale computer accounts, and so forth—what kind of ongoing maintenance should you be performing in AD? Backups are obviously important. As I've mentioned already, my preference is for continual backups made by a disk‐to‐disk recovery system rather than tape, but if tape's what you've got, then at least use that.
DiskDiskTape
By the way, just because I advocate disk‐to‐disk backups doesn't mean I don't see the value of tape, especially for getting a copy of your backups safely offsite. Most disk‐to‐disk systems provide support for making a second tapebased backup for just that purpose. And because you're essentially "backing up the backup," you can enjoy longer backup windows without affecting the production environment.
Check the logs and make sure that both AD and the File Replication Service (FRS) aren't generating anything alarming. With a continual monitoring solution (like System Center Operations Manager or something similar), you can simply let the solution keep track and alert you if there's a problem.
Also keep an eye on disk space on whatever volume contains the AD databases. Again, a monitoring solution can be used to alert you when disk space gets low, so this doesn't have to be a manual task. You should also have a plan in place to regularly defragment that logical disk—third‐party defrag utilities can do so continuously or on a routine maintenance schedule, or you can use the native defrag tool on a regular basis. Once a quarter works for many of my consulting clients.
Periodically review the log to look for replication problems—just being proactive, here. A monitoring solution can do this routinely and alert you to any problems, but it's always good to just run some of the replication monitoring tools (discussed in previous chapters) to make sure everything is working smoothly.
Finally, take time each month or so to run the BPA model for AD (on Win2008R2 and later). You can do this in PowerShell or via Server Manager (Figure 6.5 shows where to find it in Server Manager). The BPA is a collection of Microsoft guidelines for properly configuring AD and other server roles; running the model on a regular basis helps ensure that you keep AD properly configured over the long term for better security, performance, reliability, and so forth.
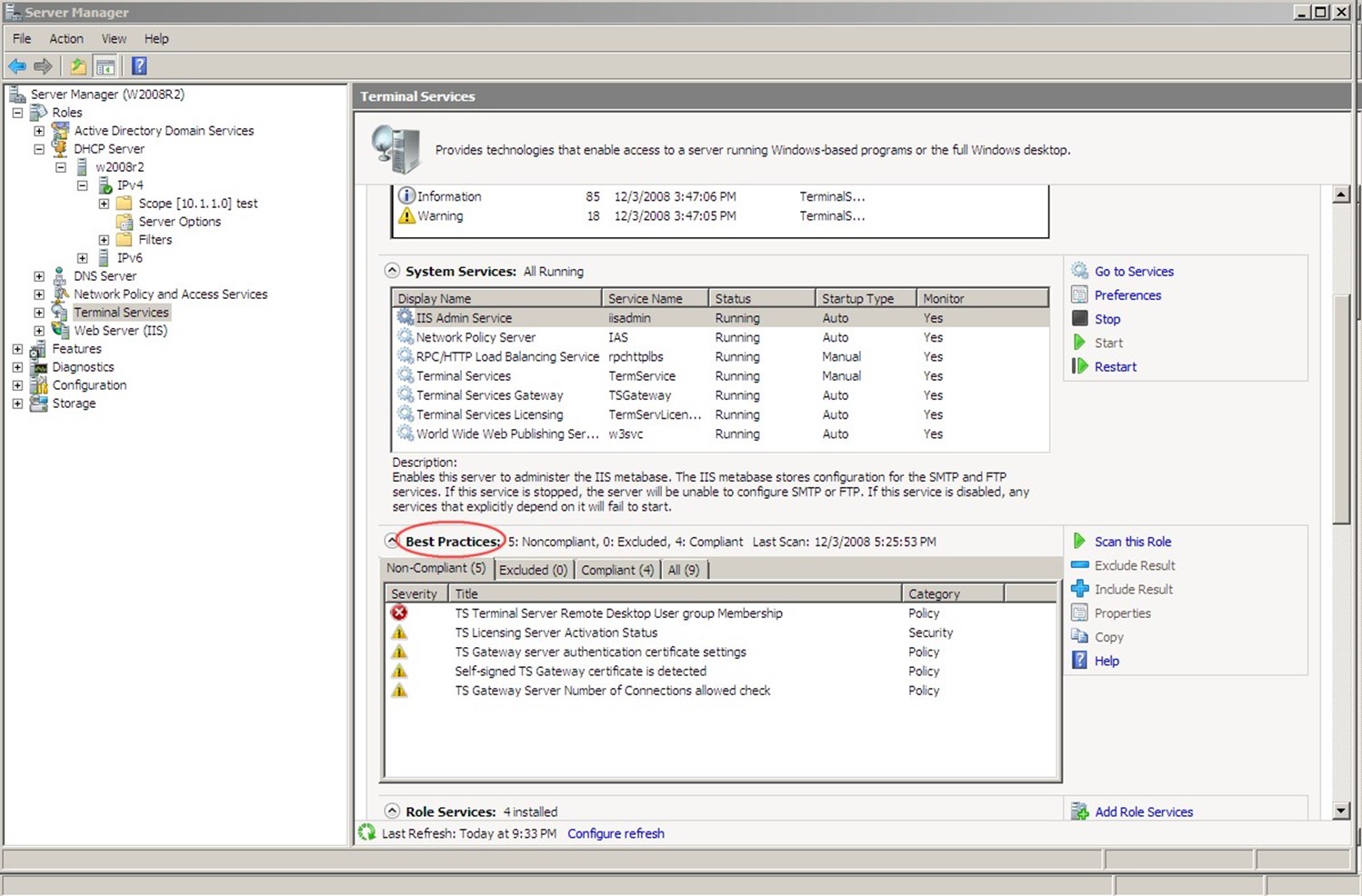
Figure 6.5: The BPA in Server Manager.
Most maintenance in AD is that business‐level, object‐focused kind of maintenance: stale computer accounts and so forth. AD is largely self‐maintaining otherwise, meaning you just need to glance at it occasionally to make sure everything's working smoothly.
Active Directory Lightweight Directory Services
In the Windows Server 2003 timeframe, Microsoft introduced Active Directory Application Mode, charmingly referred to as ADAM. These days, ADAM has grown up and changed his name to ADLDS (or AD LDS, if you prefer): Active Directory Lightweight Directory Services, which is distinct from the AD directory service that we're usually referring to when we just say "Active Directory." In this short chapter, we'll explore what AD LDS is all about, when you should (and shouldn't) use it, and how to perform basic troubleshooting and auditing with it.
What Is AD LDS?
Generally speaking, AD LDS is the same as regular AD in every way, except AD LDS doesn't perform authentication for your entire network. AD LDS is positioned as a "mode" of AD that provides directory service specifically for applications. Microsoft created AD LDS in part to address the reticence people have around extending the schema of their regular directory. Schema extensions are, after all, permanent, and nobody likes to make that kind of permanent extension to the main directory. What if you stop using the application after a few years? Its extensions hang around forever. So AD LDS gives applications a separate directory in which to store their "stuff."
AD LDS uses the exact same programming APIs as AD DS (Active Directory Domain Services, or the "normal" AD), so programmers don't have to take any special steps. AD LDS can operate entirely independently or it can operate with replication. Because it isn't part of your main domain, AD LDS also gives you a way of more easily and safely delegating control over applications' directory use. Someone can be in charge of an AD LDS install and have zero control over the main directory.
AD LDS does not, however, have any of the infrastructure components of AD DS. It isn't a directory service for the Windows operating system (OS), so clients can't authenticate to it. AD LDS can use your normal domain for authentication, which I'll discuss in a second. Thus, AD LDS can be a part of your domain in much the same way that any application could be. AD LDS doesn't have Flexible Single Master Operations (FSMO) roles or many of the other infrastructure elements we associate with the full AD DS. In addition, Microsoft Exchange can't utilize AD LDS because AD LDS doesn't support the Message Application Programming Interface (MAPI) or support authentication.
AD LDS can be run on a wider array of operating systems—the original ADAM, for example, ran fine on Windows XP. You can even run multiple instances of AD LDS on a single machine. An AD LDS instance isn't called a "domain controller" because the instance doesn't provide true domain controller functionality; instead, it is referred to as a "data store" or simply "AD LDS instance."
Partitions
AD LDS consists of a configuration and schema partition, much like AD DS. It also includes one or more application partitions, which is where applications store their data. Data, as in AD DS, is stored as objects, and the schema defines which object classes are available and what attributes those classes can use. Just as in AD DS, the configuration partition contains the internal configuration settings that make the system work.
When you install AD LDS, you have the option to create a unique instance or a replica of an existing instance, as Figure 7.1 shows. Replicas are how you provide scalability for AD LDS in instances where a single server can't keep up with the applications' demands. You can replicate the configuration and schema partitions of AD LDS, and select specific application partitions to replicate.
Figure 7.1: Creating a unique or replica AD LDS instance.
Synchronizing With AD DS
To synchronize AD LDS with a normal AD DS domain, you first have to export your directory's schema and load it into AD LDS. That way, AD LDS can "see" all of your normal domain's objects. AD LDS installs an AD Schema Analyzer tool, and you can use its Load Target Schema option (see Figure 7.2) to load the schema from an existing domain controller.
Figure 7.2: Loading the schema from a domain controller.
Replication
AD LDS instances can replicate with each other. Just as in AD DS, replication in AD LDS provides both fault tolerance and load balancing for the services provided by AD LDS.
Before configuring replication, it's important to configure the AD LDS service to run under a user account. In addition, ensure that the computers hosting AD LDS are in the same (or trusted) domains. Each instance's service should be running under the same user account, not the built‐in Network Service account.
AD LDS replicates data based on a configuration set. All AD LDS instances joined to the same configuration set will replicate a common configuration partition, a common schema partition, and whatever application partitions are configured in the configuration set. You can—very roughly—think of a configuration set as a domain from AD DS, meaning that all the AD LDS instances in the same configuration set will contain the same data. One trick is that an AD LDS instance can contain application partitions beyond those in the configuration set. Any application partitions in the configuration set will be shared with all instances replicating that set; any application partitions outside the configuration set will be unique to the instance where they live. Any AD LDS instance can participate in only one configuration set at a time, so if you have application partitions outside of a configuration set, those will not be replicated.
AD LDS supports the same kind of site and site link objects as AD DS, which are used to create and calculate the replication topology. I've written about replication earlier in this guide, and pretty much everything you know about AD replication—and sites and site links—applies to AD LDS as well. Replication within a site—that is, between instances on the same local area network (LAN)—is automatic and more or less real‐time. Beyond setting up configuration sets to determine what will replicate, you don't have to do anything. Between sites, however, you must define site link objects—something that you don't have to do in AD DS. Intersite replication also requires you to set up the replication schedule, frequency, and availability—something you can do in AD DS, but which many admins don't manually configure.
You can also override the automatic intrasite replication settings to specify a schedule, frequency, and so on.
Authentication
I technically lied about AD LDS not doing authentication. What it can't do is authenticate a Windows computer in the way that AD DS can. AD LDS can absolutely provide custom authentication for an application, and a lot of people use it as the directory for, say, an extranet Web application. Essentially, you're just using AD LDS to store custom user objects rather than sticking that information into a traditional relational database, which is what a lot of developers do. AD LDS is optimized for read access, making it a very quick and simple operation to look up a user, validate their password, and so forth.
You'll also see folks using AD LDS when they have an application that requires simple LDAP authentication and that wants to store data in the LDAP directory but they don't want that to be their main domain. AD LDS does support the full LDAP protocol, including
authentication, so it can work well in that instance. The application would provide a user's X.500 Distinguished Name (DN) and password. AD LDS' security policy for password complexity, account lockout, and so forth are enforced by the local computer's security policy rather than a GPO (AD LDS doesn't do GPOs). However, if the computer is a member of a domain and a GPO applies to it that sets password complexity or other account policies, then those will obviously apply to AD LDS as well. Unfortunately, LDAP does transmit passwords in clear text if you aren't using LDAP over SSL, so be aware of that limitation.
AD LDS also supports Windows principal authentication, also known as SSPI authentication. This permits someone to use their AD DS domain account to authenticate to an AD LDS instance, or to use local user and group accounts created on the machine hosting AD LDS. To use domain accounts, AD LDS must be a member of the domain. In a domain environment, authentication happens with the Kerberos protocol, providing better security, mutual authentication, and complete protection of users' passwords (although it can fall back to NTLM authentication depending on your domain policies for that).
AD LDS also supports proxy authentication, also known as bind redirection, in which users authenticate using an AD LDS account (that is, a user account stored in AD LDS) but can use their AD DS domain password. Again, the AD LDS host computer needs to be a member of the AD DS domain, and you'll usually need some kind of account synchronization tool like ForeFront Identity Manager to synchronize the objectSID from AD DS to the corresponding AD LDS user accounts. This uses LDAP, so it's important to set up LDAP over SSL to secure the domain passwords on the network.
When to Use AD LDS
AD LDS is useful whenever you have an application (other than Microsoft Exchange Server, which is a notable exception) that needs to store data in AD and you don't want to extend the schema of your main directory for that purpose. AD LDS is also a good choice if you're developing an application that will eventually integrate with AD DS. With AD LDS, you can have a locallyinstalled directory on your development or testing systems, because AD LDS can run on a broader range of OSs and doesn't have the extensive prerequisites of AD DS.
Anytime you find yourself asking, "Should we extend the schema of our directory?" then you should at least put AD LDS on the table for consideration, especially if your gut reaction to that question is, "NO!!!"
When Not to Use AD LDS
AD LDS is not a replacement for AD DS. It can't authenticate users to a domain, and it can't authenticate domain‐joined computers. Windows machines can't "join" an AD LDS instance. AD LDS is intended for use primarily by applications, often in conjunction with a normal AD DS domain.
Troubleshooting AD LDS
The biggest thing you'll wind up troubleshooting in AD LDS is replication. Fortunately, its replication works exactly like that in AD DS, so the troubleshooting sections in the earlier chapters of this guide still apply.
Auditing AD LDS
AD LDS does support change auditing, meaning you can have an event written to the Windows event logs whenever a change occurs. These events often include old and new values for object attribute changes, which can be useful for creating an audit trail for compliance. It's the same feature as in AD DS, in fact, and you enable it in the same way.
As with password policy and account lockout, the audit policy can be applied to an AD LDS server either through its local security policy or for domain‐joined computers through an appropriately‐linked GPO. Auditing works just like it does in AD DS:
- You'll typically enable auditing through a GPO, although for non‐domain hosts you can do so in the local security policy.
- Set the Security Access Control List (SACL) on the objects you want to audit.
- The account running the AD LDS service needs to have the "Generate Security Audit" user privilege on the servers where AD LDS runs. NetworkService and LocalSystem have this set by default, but if you're replicating a configuration set and using a domain user account, then you'll have to grant this privilege to that account.
In addition to auditing attribute changes (which is fairly new even for AD DS), you can in
AD LDS audit access to the directory service and audit logon events just as you can in AD DS. However, two specific settings that don't apply to AD LDS are:
- Audit Account Management—Because AD LDS objects are viewed by Windows as objects in a directory, Widows doesn't see them as "accounts" per se, even if the object's class name is "user" (and by default, AD LDS doesn't contain a "user" class).
- Audit Object Access, Audit Policy Change, Process Tracking, and System Events— The settings also don't make sense in AD LDS because they apply to things like files and policies that don't exist in AD LDS.
AD LDS doesn't come with a full suite of tools like AD DS does, although some of the normal AD DS tools will work against AD LDS. To set up a SACL, you'll use LDP.exe and its SACL editor. You can also use the Dsacls.exe command‐line utility. Simply bind the tool to your AD LDS instance (make sure you're using an admin account to do so), enumerate your partitions, and right‐click whatever object you want to apply a SACL to. As Figure 7.3 shows, you'll get a familiar‐looking dialog box in which to define the audit policy for that object.
Figure 7.3: Setting a SACL in AD LDS.
Assorted Tips and Tricks for Active Directory Troubleshooting
We're at the end of this guide, and I find myself left with several things I wish I'd mentioned earlier—except that these things don't fit neatly into any of the topics we've already discussed. So in this chapter, I'll present these seemingly‐random, yet completely‐helpful, tips for troubleshooting various aspects of Active Directory (AD).
Troubleshooting FSMO Roles
Typically, there's no good "fix" for a broken Flexible Single Master Operation (FSMO) role— you're often left to nicely transfer the role to another domain controller or, in a worst‐case scenario, seize the role on another domain controller. There are, however, some indications that tell you a FSMO role holder isn't working properly:
- If you can't add new domains, the Domain Naming Master is down. That FSMO can be down for ages without you realizing it because you probably don't often add domains.
- If users are changing their passwords but can't log on, the PDC Emulator is the likely cause. This FSMO role also plays a part in time synchronization.
- Failure of the PDC Emulator can also affect your ability to edit Group Policy Objects
- (GPOs) and prevent you from adding new domains to a forest.
- If you can't create new directory objects, you lost your RID Master—probably a while back, as domain controllers obtain RIDs in blocks and cache them.
- In a multi‐domain environment, a failed Infrastructure Master can result in incomplete group memberships, meaning users may not be able to access all of their resources.
- Domain upgrades and schema extensions can rely on the Domain Naming Master and the Schema Master, depending on what work they're doing.
The PDC Emulator is the one role you'll probably miss the soonest if something goes wrong; many of my customers keep this role on a clustered domain controller for that exact reason.
Whatever you do, don't forcibly seize a FSMO role from a domain controller unless you're taking that domain controller completely offline, demoting it (removing AD), and planning to rebuild it before it's reconnected to the network. This is especially true of the Schema Master and Domain Naming Master: Under no circumstances must two servers believe they each hold one of those roles.
Checking your FSMOs is pretty easy: Use the DCDiag tool on a domain controller in each of your domains (it's not a bad idea to run it on several domain controllers, in different sites, to make sure you get the same results). It'll check your FSMOs and report back. The next step, if a FSMO appears to be broken, is to check DNS. Really, it seems like two‐thirds of all AD problems can be traced back to a DNS issue. Make sure each FSMO role holder is properly registered in DNS, and you'll probably be fine.
Troubleshooting Domain Controllers in General
Domain controllers, by and large, "just work." Provided everything around them— replication, time sync, and so forth—is all working, you'll tend to have very little trouble with the AD database and services. When you think a domain controller is broken, start by going through a quick checklist on configuration and surrounding operations:
- Make sure the domain controller's site and subnet configuration is correct.
- Make sure time sync is working and that the domain controller's clock matches that of the domain's PDC Emulator (see the next section).
- Make sure replication is working. If a domain controller seems "broken," either replication, or some dependency like the network itself, is likely causing the problem.
- Make sure the domain controller is properly registered in DNS, and ensure that client computers and other domain controllers can properly resolve the domain controller's DNS records.
- Check the domain controller's event logs for any bad news, and deal with whatever you find.
Once you've eliminated those problems, you may in fact be looking at a broken domain controller. There are a number of things you can do to troubleshoot problems, rebuild the directory database, and so forth. Honestly, a lot of customers I work with will simply demote and re‐promote the domain controller. That rebuilds everything from scratch. It's somewhat time consuming but not necessarily more so than a protracted troubleshootingand‐repair process that may result in a re‐promotion anyway.
Troubleshooting Time Sync
Time synchronization is absolutely crucial in AD. By default, authentication traffic only allows for a 5‐minute out‐of‐sync window; let any client or domain controller get further out‐of‐sync than 5 minutes, and authentication stops working. The solution to this problem is not to extend that time window; doing so creates a higher security risk because someone can more easily capture and "replay" authentication packets against your network. Instead, fix the time‐sync problem.
Time sync is handled by a background service on all Windows computers, servers, and clients. Client computers and member servers sync time with the domain controller that authenticated them when they started; domain controllers sync with the domain controller holding the PDC Emulator FSMO role. The PDC Emulator should sync with an external, authoritative time source. The sync traffic occurs over UDP port 123, so your first step will be to make sure that port is open. Keep in mind that, by default, the PDC Emulator isn't configured to sync time, and it will repeatedly log messages to that effect until you do configure it.
The best troubleshooting tool you have is the W32tm tool, which must be run from the command line by an administrator. This tool cannot function if the Windows Time Service is running, so temporarily stop that service before running W32tm. Be sure to restart the service when you're done troubleshooting. Some specific tips—each of which must be completed by an Administrator:
- Run net time /querysntp to check time sync servers on domain controllers and workstations
- Run w32tm /resync to check sync with your domain controller
- Run w32tm /monitor /domain:domain_name to check the status of domain controller time sources.
- Run net time /domain:domain_name /set /y to try to synchronize with the local domain time source
The errors generated by those commands, if any, will tell you what needs to be fixed. Also note that the Time Service won't always immediately correct an out‐of‐sync local clock: If the local clock is faster than its time source but less than 3 minutes out of sync, the Time Service will merely slow the clock so that it eventually comes back into sync. When doing so, the Time Service will check the time about every 45 minutes until the clock is in‐sync for three consecutive checks. The service then resumes its normal behavior of checking the clock every 8 hours.
You can find more step‐by‐step tips on troubleshooting time sync at http://cainmanor.com/tech/windows‐time‐troubleshooting/.
Troubleshooting Kerberos
Provided time sync is working, Kerberos will generally work as advertised. Try to avoid fiddling with Kerberos' configuration (which can be done through Group Policy), as tweaking Kerberos settings incorrectly can lead to problems. Most Kerberos issues stem from underlying DNS or network connectivity issues; start by assuming that a problem is with DNS or the network and resolve those problems first.
Specific symptoms of a possible Kerberos issue:
- Users or computers can't log on or can't access network resources, and Kerberos is the protocol in use. You do have to check this, as sometimes a different protocol can be used and troubleshooting Kerberos is just a waste of your time.
- The event log will show errors related to Kerberos Key Distribution Center (KDC), Local Security Authority Server (LsaSrv), or Net Logon (Netlogon) services.
- Failure events in the Security log will indicate which protocol is being used: Enable auditing of failed logons, if you haven't done so, to see if any of these audits are logged. Note that enabling this level of auditing can increase log volume significantly; be sure to turn off this setting if it isn't normally on in your environment.
To troubleshoot Kerberos:
- You'll need to be an Administrator on the computers involved.
- Obviously, make sure you're on the latest service pack, hotfixes, and whatnot. Restart the computer(s) affected.
- Make sure DNS is working and that the affected computer can resolve a domain controller via DNS.
- Make sure all domain controllers a client might use are accessible and can be resolved via DNS.
- Check time sync.
Install the Windows Support Tools (from the server installation DVD), including Ldifde, LDP, Setspn, and Tokensz. You should also enable logon failure auditing because those events can contain useful diagnostic information (see http://technet.microsoft.com/enus/library/cc736727(WS.10).aspx for instructions on doing so).
Finally, start troubleshooting. Use the step‐by‐step guide at http://technet.microsoft.com/en‐us/library/cc786325(WS.10).aspx to use the Windows Support Tools to resolve specific problem areas.
Troubleshooting RIDs
Relative Identifiers (RIDs) are used to ensure that a unique ID number can be assigned to each directory object created by a domain controller. The RID Master FSMO Role hands out unique RIDs in batches to domain controllers; the controllers cache those RIDs and use them when creating new objects. When a domain controller runs out of RIDs, it asks the RID Master for more. Earlier in this chapter, I mentioned that an inability to create new objects is a sign that the RID Master is either broken, offline, or inaccessible to domain controllers (inaccessibility is often a DNS issue or network infrastructure problem).
There are a number of event log entries you can watch for:
- 16642 indicates that the domain controller is out of RIDs. It should have requested more; check the RID Master and restart the domain controller.
- 16643 indicates that the domain controller hasn't gotten a pool of RIDs yet—often because the RID Master isn't accessible.
- 16644 tells you that the domain is out of RIDs. This is a Bad Situation and shouldn't normally occur, even in huge domains. The limit of RIDs is a bit over 1 billion (1,073,741,825, to be exact).
- 16645 says that the domain controller just assigned its last RID and couldn't get more. Again, check the availability of, and connectivity to, the RID Master.
- 16646 indicates a processing problem where a domain controller tried to use an invalid RID. Force the domain controller to invalidate its RID pool, which should force it to ask for a new one.
- 16647 means the domain controller is requesting a new RID pool. This is good.
- 16648 means a domain controller got a new RID pool—this is excellent news.
- 16651 means a RID pool request failed—Bad News. The domain controller will retry—look for another 16647 event.
Troubleshooting Object Deletion
It's important to understand how object deletion occurs in AD so that you can troubleshoot problems:
- When you delete an object, it is actually just "marked as deleted," a process called tombstoning.
- Like any other change to an object, the tombstone change is replicated, thus "deleting" the object on all other domain controllers.
- The old default value for tombstone clean‐up was 60 days; as of Windows Server 2003, it was set to 180 days. After this period, each domain controller permanently deletes tombstoned objects.
There are some consequences to this behavior:
- If you restore a domain controller from a backup that is older than the clean‐up window, or connect a domain controller that has been offline longer than that, deleted objects will come back because the old domain controller (or its backup) will re‐create the object.
- The "Active Directory Recycle Bin" feature introduced in Windows Server 2008 R2 actually copies deleted objects to a separate area of the directory rather than deleting them. Again, reviving a very old domain controller can thus make objects "reappear" in their original location.
Most object deletion issues can be prevented by simply never allowing an older domain controller, or a backup of one, to be reconnected to the network.
Troubleshooting Replication
Replication is probably the trickiest thing to troubleshoot in AD. Before you dive in, I have some recommendations that can make replication less prone to problems:
- Keep your sites and subnets up‐to‐date. This is really crucial, as replication relies on the topology of your sites and subnets. A subnet is a single IP subnet—Class A, Class B, Class C, whatever you use. A site is a collection of subnets that all exist in the same LAN‐quality bandwidth—that is, all the subnets with a 100Gbps or better Ethernet connection.
- Make your site links reflect your physical WAN architecture, and avoid creating site bridge links unless you absolutely must do so in order to speed replication to farflung sites. Allowing the directory to calculate its own replication topology based on your physical WAN is the best course of action.
Assuming you haven't dorked around with your site, subnet, and site link configuration, you'll need some tools to start troubleshooting things. Microsoft provides a good walkthrough at http://technet.microsoft.com/en‐us/library/cc738415(WS.10).aspx; personally, I much prefer third‐party tools that can help me visualize the replication topology and that can check it for me and even initiate fixes. Quest's Spotlight on Active Directory is one such tool I've used; search for "Active Directory replication tool" in your favorite search engine and you'll find others.
Troubleshooting DNS
DNS, as I've indicated elsewhere in this chapter, turns out to be the root cause for a lot of AD troubles. In fact, I counsel all of my customers to get a solid AD‐specific DNS monitoring tool in place to continuously check DNS operations and proactively alert them if something goes wrong. Why "AD‐specific?" Because of the way in which AD uses DNS. A tremendous number of DNS records get added by domain controllers, and a monitoring solution that's aware of those things can do a better job of monitoring the overall infrastructure.
For example, a solution can check the AD itself to see which domain controllers exist, then verify that each one has registered all the proper DNS records, and then verify that DNS is properly returning those records, and then verify that the computers are reachable using the data in those records—covering the entire loop of possible problems, essentially. Such monitoring tools are nearly always commercial, meaning you'll have to pay a bit for them.
There are some obvious first steps to making sure that DNS is working properly. Each of these, however, requires that you know what DNS should be doing. When sitting down at a client computer, for example, you need to know which domain controllers it should expect to see, what DNS records it should expect to receive from a query, and so forth. All you can do is verify that DNS is returning what you expect; if it doesn't, you've found your problem. If you don't know what should be happening, however, you'll never find the problem. Those first steps:
- Clear the client DNS cache by running ipconfig /flush.
- Check the DNS cache to make sure you don't have any static records from a hosts file.
- Use Nslookup to perform the same queries a client computer would, and verify the results. What you query is going to depend on what situation you're trying to replicate, of course. http://technet.microsoft.com/en‐us/library/bb726934.aspx has a great list of starting points, particularly with regard to improper DNS server configuration.
With those basics out of the way, you can start troubleshooting. DNS troubleshooting is a massive topic all by itself, and there are several entire books on the subject, so I can't go into a great deal of depth here. But http://technet.microsoft.com/en‐us/library/cc787724(WS.10).aspx is a good guide to getting started and covers some of the most common problems.
Troubleshooting Permissions
Last up is the process of troubleshooting permissions. This is when someone should have permission to something in AD but they don't—or the opposite, when they do but shouldn't. Really, this isn't much different than troubleshooting the same problem in the
Windows file system. Keep in mind the following facts:
- Permissions can be applied directly at an organizational unit (OU) or container, then inherited by objects.
- Permissions can be applied directly on an object.
A user's effective permissions are the combination of every inherited parent OU permission plus the permissions directly on the object. A "Deny" permission anywhere in that chain of inheritance will override an "Allow" that occurs anywhere else. You can minimize the complexity of troubleshooting by never applying permissions directly to objects and by minimizing the number of OUs you apply permissions to. That way, you have fewer places to look.
To troubleshoot permissions in Active Directory Users and Computers, you'll first need to enable Advanced Features from the View menu. Otherwise, objects' Security tabs aren't even visible. Tells you how much Microsoft thinks you should mess with this stuff!
Once on the Security tab for an object, click Advanced. Then use the Effective Permissions tab. This is probably the easiest way to resolve the inheritance of permissions and see the final, effective permissions a given user has over a given object or container. Just select the user you're troubleshooting, then review the permissions.